第3章 微积分与线性代数
原书 PDF 第 49 页原著:Xinfeng Zhou,A Practical Guide to Quantitative Finance Interviews(2008)。
本页由 GPT 视觉模型直接依据扫描页识别、翻译和公式排版。
查看本页原始扫描图

微积分和线性代数是量化金融中许多高级数学主题的基础。因此,请准备好回答一些微积分或线性代数问题——其中许多问题可能会融入更复杂的问题中——在量化面试中。由于大多数测试的微积分和线性代数知识都易于掌握,边际收益远远大于您花时间复习关键科目知识所付出的时间。如果您的微积分或线性代数记忆有些生疏,请花些时间复习您的大学课本! 不用说,将任何微积分/线性代数书籍浓缩成一章是极其困难的。这也不是我的意图。本章仅关注量化面试中经常出现的一些核心微积分/线性代数概念。并且,除非必要,否则不涵盖这些概念的证明、细节甚至注意事项。如果您不熟悉任何概念,请参考您最喜欢的微积分/线性代数书籍以获取详细信息。
3.1 极限与导数
导数基础
让我们从极限和导数中使用的一些基本定义和方程开始。尽管符号可能不同,但您可以在任何微积分教科书中找到这些材料。导数: 令 \(y=f(x)\),则 \[ f'(x) = \frac{dy}{dx} = \lim_{\Delta x \to 0}\frac{\Delta y}{\Delta x} = \lim_{\Delta x \to 0}\frac{f(x+\Delta x)-f(x)}{\Delta x}. \] 乘积法则: 如果 \(u = u(x)\) 和 \(v = v(x)\) 且它们各自的导数存在,则 \[ \frac{d(uv)}{dx} = u\frac{dv}{dx} + v\frac{du}{dx}, \quad (uv)' = u'v + uv' \] 商法则: \[ \frac{d}{dx}\left(\frac{u}{v}\right) = \frac{v\frac{du}{dx} - u\frac{dv}{dx}}{v^2}, \quad \left(\frac{u}{v}\right)' = \frac{u'v - uv'}{v^2} \] 链式法则: 如果 \(y = f(u(x))\) 且 \(u = u(x)\),则 \[ \frac{dy}{dx} = \frac{dy}{du}\frac{du}{dx} \] 广义幂法则: \(\frac{dy^n}{dx} = ny^{n-1}\frac{dy}{dx}\) 对所有 \(n \neq 0\) 一些有用的方程:
原书 PDF 第 50 页查看本页原始扫描图

\[ a^x = e^{x \ln a} \] \[ \ln(ab) = \ln a + \ln b \] \[ e^x = \lim_{n \to \infty} \left(1 + \frac{x}{n}\right)^n \] \[ \lim_{x \to 0} \frac{\sin x}{x} = 1 \] \[ \lim_{x \to 0} (1+x)^k = 1+kx \text{ 对任意 } k \] \[ \lim_{x \to \infty} (\ln x / x^r) = 0 \text{ 对任意 } r > 0 \] \[ \lim_{x \to \infty} x^r e^{-x} = 0 \text{ 对任意 } r \] \[ \frac{d}{dx} e^u = e^u \frac{du}{dx} \] \[ \frac{d}{dx} a^u = (a^u \ln a) \frac{du}{dx} \] \[ \frac{d}{dx} \ln u = \frac{1}{u} \frac{du}{dx} = \frac{u'}{u} \] \[ \frac{d}{dx} \sin x = \cos x, \quad \frac{d}{dx} \cos x = -\sin x, \quad \frac{d}{dx} \tan x = \sec^2 x \]
求 \(y = \ln x^{\ln x}\) 的导数?
解:这是一个测试你对基本导数公式——特别是链式法则和乘积法则——掌握程度的好问题。令 \(u = \ln y = \ln(\ln x^{\ln x}) = \ln x \times \ln(\ln x)\)。应用链式法则和乘积法则,我们有 \[ \frac{du}{dx} = \frac{d(\ln y)}{dx} = \frac{1}{y} \frac{dy}{dx} = \frac{d(\ln x)}{dx} \times \ln(\ln x) + \ln x \times \frac{d(\ln(\ln x))}{dx} = \frac{1}{x} \ln(\ln x) + \frac{\ln x}{x} \] 为了推导 \( \frac{d(\ln(\ln x))}{dx} \),我们再次使用链式法则,令 \(v = \ln x\): \[ \frac{d(\ln(\ln x))}{dx} = \frac{d(\ln v)}{dv} \frac{dv}{dx} = \frac{1}{v} \times \frac{1}{x} = \frac{1}{\ln x} \times \frac{1}{x} = \frac{1}{x \ln x} \] 所以, \[ \frac{1}{y} \frac{dy}{dx} = \frac{\ln(\ln x)}{x} + \frac{\ln x}{x \ln x} \implies \frac{dy}{dx} = \frac{y}{x} (\ln(\ln x) + 1) = \frac{\ln x^{\ln x}}{x} (\ln(\ln x) + 1). \]
补充说明: 这里有一个小技巧需要注意。在计算 \(u = \ln y\) 时,我们利用了幂的对数性质:\(\ln(a^b) = b \ln a\)。所以 \(\ln(\ln x^{\ln x}) = \ln x \cdot \ln(\ln x)\)。另外,题目提示中提到,对于形如 \(y = f(x)^{g(x)}\) 的函数求导,一个常用的技巧是两边取自然对数,因为 \(d(\ln y)/dx = (1/y) \cdot (dy/dx)\),可以简化计算。
最大值与最小值
导数 \(f'(x)\) 本质上是曲线 \(y = f(x)\) 的切线斜率,也是 \(y\) 关于 \(x\) 的瞬时变化率(速度)。在点 \(x=c\) 处,如果 \(f'(c)>0\),则 \(f(x)\) 在 \(c\) 点是增函数;如果 \(f'(c)<0\),则 \(f(x)\) 在 \(c\) 点是减函数。局部最大值或最小值: 假设 \(f(x)\) 在 \(c\) 点可导,并且在包含 \(c\) 的开区间上有定义。如果 \(f(c)\) 是 \(f(x)\) 的局部最大值或局部最小值,则 \(f'(c)=0\)。二阶导数检验: 假设 \(f(x)\) 的二阶导数 \(f''(x)\) 在 \(c\) 点附近连续。如果 \(f'(c)=0\) 且 \(f''(c)>0\),则 \(f(x)\) 在 \(c\) 点有局部最小值;
如果 \(f'(c)=0\) 且 \(f''(c)<0\),则 \(f(x)\) 在 \(c\) 点有局部最大值。
补充说明: 一阶导数为零的点称为驻点或临界点。但驻点不一定是极值点(例如 \(y=x^3\) 在 \(x=0\) 处)。二阶导数检验通过判断函数在驻点附近的凹凸性(二阶导数的正负)来区分是极大值还是极小值。
不计算数值结果,你能告诉我哪个数更大,\(e^\pi\) 还是 \(\pi^e\)?
解:我们取 \(e^\pi\) 和 \(\pi^e\) 的自然对数。左边是 \(\pi \ln e\),右边是 \(e \ln \pi\)。如果 \(e^\pi > \pi^e\),则 \(e^\pi > \pi^e \Leftrightarrow \pi \ln e > e \ln \pi \Leftrightarrow \frac{\ln e}{e} > \frac{\ln \pi}{\pi}\)。这是真的吗?这取决于函数 \(f(x) = \frac{\ln x}{x}\) 在 \(e\) 到 \(\pi\) 之间是增函数还是减函数。对 \(f(x)\) 求导,我们得到 \(f'(x) = \frac{1/x \cdot x - \ln x}{x^2} = \frac{1 - \ln x}{x^2}\),当 \(x>e\) 时(此时 \(\ln x > 1\)),\(f'(x)<0\)。
事实上,对于所有 \(x>0\),\(f(x)\) 在 \(x=e\) 时取得全局最大值。所以 \(\frac{\ln e}{e} > \frac{\ln \pi}{\pi}\),并且 \(e^\pi > \pi^e\)。替代方法: 如果你熟悉泰勒级数(我们将在 3.4 节讨论),你可以将泰勒级数应用于 \(e^x\):\(e^x = \sum_{n=0}^{\infty} \frac{1}{n!} = 1 + \frac{x}{1!} + \frac{x^2}{2!} + \frac{x^3}{3!} + \dots\)。所以 \(e^x > 1+x\),对所有 \(x>0\) 成立。
令 \(x = \pi/e - 1\),则 \(e^{\pi/e} > 1 + (\pi/e - 1) = \pi/e \Leftrightarrow e^{\pi/e} / (\pi/e) > 1 \Leftrightarrow e^\pi / \pi^e > 1 \Leftrightarrow e^\pi > \pi^e\)。
补充说明: 提示中再次提到,由于自然对数函数 \(\ln x\) 是单调递增的,所以比较两个正数 \(a\) 和 \(b\) 的大小,等价于比较 \(\ln a\) 和 \(\ln b\) 的大小。这是处理指数型比较问题的常用技巧。
洛必达法则
假设函数 \(f(x)\) 和 \(g(x)\) 在 \(x \to a\) 时可导,且 \(\lim_{x \to a} g'(a) \neq 0\)。进一步假设 \(\lim_{x \to a} f(a) = 0\) 且 \(\lim_{x \to a} g(a) = 0\) 或者 \(\lim_{x \to a} f(a) \to \pm \infty\) 且 \(\lim_{x \to a} g(x) \to \pm\infty\),则 \(\lim_{x \to a} \frac{f(x)}{g(x)} = \lim_{x \to a} \frac{f'(x)}{g'(x)}\)。洛必达法则将极限从不定形式转化为确定形式。
当 \(x \to \infty\) 时,\(e^x / x^2\) 的极限是多少?当 \(x \to 0^+\) 时,\(x^2 \ln x\) 的极限是多少?
解:\(\lim_{x \to \infty} \frac{e^x}{x^2}\) 是洛必达法则的一个典型例子,因为 \(\lim_{x \to \infty} e^x = \infty\) 且 \(\lim_{x \to \infty} x^2 = \infty\)。应用洛必达法则,我们得到 \[ \lim_{x \to \infty} \frac{f(x)}{g(x)} = \lim_{x \to \infty} \frac{e^x}{x^2} = \lim_{x \to \infty} \frac{f'(x)}{g'(x)} = \lim_{x \to \infty} \frac{e^x}{2x} \] 结果仍然具有 \(\lim_{x \to \infty} f(x) = \lim_{x \to \infty} e^x = \infty\) 和 \(\lim_{x \to \infty} g(x) = \lim_{x \to \infty} 2x = \infty\) 的性质,所以我们可以再次应用洛必达法则: \[ \lim_{x \to \infty} \frac{f(x)}{g(x)} = \lim_{x \to \infty} \frac{e^x}{2x} = \lim_{x \to \infty} \frac{f'(x)}{g'(x)} = \lim_{x \to \infty} \frac{d(e^x)/dx}{d(2x)/dx} = \lim_{x \to \infty} \frac{e^x}{2} = \infty \] 乍一看,洛必达法则似乎不适用于 \(\lim_{x \to 0^+} x^2 \ln x\),因为它不符合 \(\lim_{x \to a} \frac{f(x)}{g(x)}\) 的形式。
然而,我们可以将原极限重写为 \(\lim_{x \to 0^+} \frac{\ln x}{x^{-2}}\),此时 \(\lim_{x \to 0^+} x^{-2} = \infty\) 且 \(\lim_{x \to 0^+} \ln x = -\infty\)。因此,我们现在可以应用洛必达法则: \[ \lim_{x \to 0^+} x^2 \ln x = \lim_{x \to 0^+} \frac{\ln x}{x^{-2}} = \lim_{x \to 0^+} \frac{d(\ln x)/dx}{d(x^{-2})/dx} = \lim_{x \to 0^+} \frac{1/x}{-2/x^3} = \lim_{x \to 0^+} \frac{x^2}{-2} = 0 \]
补充说明: 洛必达法则适用于“0/0”或“∞/∞”型的不定式。对于其他类型的不定式,如“0·∞”、“∞-∞”、“1^∞”等,通常需要通过代数变形(如本例中将乘积化为商)将其转化为“0/0”或“∞/∞”型,然后再应用法则。
3.2 积分
积分基础
再次,让我们从一些用于积分的基本定义和方程开始。 如果我们能找到一个函数 \(F(x)\) 使得其导数为 \(f(x)\),那么我们就称 \(F(x)\) 为 \(f(x)\) 的原函数或反导数。 如果 \(f(x) = F'(x)\),则 \(\int_a^b f(x) dx = \int_a^b F'(x) dx = [F(x)]_a^b = F(b) - F(a)\)。
原书 PDF 第 53 页查看本页原始扫描图

\[ \frac{dF(x)}{dx} = f(x), \quad F(a) = y_a \Rightarrow F(x) = y_a + \int_{a}^{x} f(t)dt \] 广义幂法则的逆运算: \[ \int u^k du = \frac{u^{k+1}}{k+1} + c \quad (k \neq 1), \text{ 其中 } c \text{ 是任意常数。} \] 换元积分法: \[ \int f(g(x)) \cdot g'(x) dx = \int f(u) du \quad \text{令 } u = g(x), \quad du = g'(x)dx \] 定积分的换元: \[ \int_{a}^{b} f(g(x)) \cdot g'(x) dx = \int_{g(a)}^{g(b)} f(u) du \] 分部积分法: \[ \int u dv = uv - \int v du \]
A. $\ln(x)$ 的积分是什么?
解: 这是一个分部积分法的例子。令 $u = \ln x$ 且 $v = x$,我们有 \[ d(uv) = vdu + udv = (x \cdot \frac{1}{x})dx + \ln x dx, \] \[ \therefore \int \ln x dx = x \ln x - \int dx = x \ln x - x + c, \quad \text{其中 } c \text{ 是任意常数。} \]
补充说明: 分部积分法的核心思想是“对乘积求导法则”的逆运算。这里选择 $u = \ln x$ 是因为它的导数 $du = (1/x)dx$ 更简单,而 $dv = dx$ 的积分 $v = x$ 也很简单,从而简化了原积分。
B. $\sec(x)$ 从 $x=0$ 到 $x=\pi/6$ 的积分是多少?
解: 显然这个问题直接关系到三角函数的微分/积分。虽然所有基本三角函数都有导数公式,但我们只需要记住其中两个: \[ \frac{d}{dx} \sin x = \cos x, \quad \frac{d}{dx} \cos x = -\sin x. \] 其余的可以利用乘积法则或商法则推导出来。例如, \[ \frac{d \sec x}{dx} = \frac{d(1/\cos x)}{dx} = \frac{\sin x}{\cos^2 x} = \sec x \tan x, \] \[ \frac{d \tan x}{dx} = \frac{d(\sin x/\cos x)}{dx} = \frac{\cos^2 x + \sin^2 x}{\cos^2 x} = \sec^2 x. \] \[ \therefore \frac{d(\sec x + \tan x)}{dx} = \sec x(\sec x + \tan x). \]
原书 PDF 第 54 页查看本页原始扫描图

由于导数中出现了 $(\sec x + \tan x)$ 项,我们也有 \[ \frac{d \ln |\sec x + \tan x|}{dx} = \frac{\sec x (\sec x + \tan x)}{(\sec x + \tan x)} = \sec x \] \[ \Rightarrow \int \sec x dx = \ln |\sec x + \tan x| + c \] 以及 \[ \int_{0}^{\pi/6} \sec x dx = \ln(\sec(\pi/6) + \tan(\pi/6)) - \ln(\sec(0) + \tan(0)) = \ln(\sqrt{3}) \]
积分的应用
A. 假设两个半径均为 1 的圆柱体以直角相交,且它们的中心也相交。求其相交部分的体积。 解: 这个问题是积分在体积计算中的一个应用。对于这类应用题,最困难的部分是正确地建立积分表达式。计算三维体积的一般积分函数是 $V = \int_{z_1}^{z_2} A(z)dz$,其中 $A(z)$ 是立体被垂直于 z 轴的平面在坐标 z 处截得的横截面积。这里的关键是找到横截面积 $A$ 关于 $z$ 的正确表达式。
另一种方法需要更好的三维想象力。让我们想象一个内切于两个圆柱体的球体,因此它也内切于这个相交体。这个球体的半径应为 $r/2$。在每个垂直于 z 轴的截面上,来自球体的圆也内切于来自相交体的正方形。所以 \[ A_{\text{圆}} = \frac{\pi}{4} A_{\text{正方形}}. \] 由于这对所有 $z$ 值都成立,我们有 \[ V_{\text{球体}} = \frac{4}{3} \pi \left(\frac{r}{2}\right)^3 = \frac{\pi}{4} V_{\text{相交体}} \Rightarrow V_{\text{相交体}} = \frac{16}{3} r^3 = 16/3. \]
原书 PDF 第 55 页
查看本页原始扫描图

B. 雪在中午之前的某个时刻开始以恒定速率下落。剑桥市在中午派出了一辆扫雪车清理从麻省理工学院到哈佛大学的麻省大道。扫雪车每分钟清除的雪量恒定。在下午 1 点,它前进了 2 英里;在下午 2 点,它前进了 3 英里。雪是什么时候开始下的?
解:
让我们将中午记为时间 0,并假设雪在中午前 $T$ 小时开始下。扫雪车移动的速度与雪的垂直横截面积成反比:$v = c_1 / A(t)$,其中 $v$ 是扫雪车的速度,$c_1$ 是一个常数,代表扫雪车每小时能清除的雪的体积,而 $A(t)$ 是雪的横截面积。如果将 $t$ 定义为中午之后的时间,我们还有 $A(t) = c_2(t+T)$,其中 $c_2$ 是横截面积每小时的增长速率(因为雪以恒定速率下落)。所以 $v = \frac{c_1}{c_2(t+T)} = \frac{c}{t+T}$,其中 $c = \frac{c_1}{c_2}$。
进行积分,我们有 \[ \int_0^1 \frac{c}{T+t} dt = c \ln(1+T) - c \ln T = c \ln\left(\frac{1+T}{T}\right) = 2, \] \[ \int_0^2 \frac{c}{T+t} dt = c \ln(2+T) - c \ln T = c \ln\left(\frac{2+T}{T}\right) = 3 \] 从这两个方程,我们得到 \[ \left(\frac{1+T}{T}\right)^3 = \left(\frac{2+T}{T}\right)^2 \Rightarrow T^2 - T + 1 = 0 \Rightarrow T = (\sqrt{5}-1)/2. \]
原书 PDF 第 56 页查看本页原始扫描图

总的来说,这个问题虽然相当直接,但测试了分析技能、积分知识和代数知识。
利用积分求期望值
积分被广泛用于计算连续随机变量的无条件或条件期望值。在第 4 章,我们将展示它在概率和统计中的价值。这里我们仅用一个例子来展示其应用: 如果 X 是一个标准正态随机变量,$X \sim N(0, 1)$,那么 $E[X | X > 0]$ 是多少?解: 由于 $X \sim N(0, 1)$,x 的概率密度函数为 $f(x) = \frac{1}{\sqrt{2\pi}}e^{-1/2x^2}$,并且我们有 $E[X | X > 0] = \int_{0}^{\infty} xf(x)dx = \int_{0}^{\infty} x\frac{1}{\sqrt{2\pi}}e^{-1/2x^2} dx$。因为 $d(-1/2x^2) = -x dx$ 且 $\int e^u du = e^u + c$,其中 c 是任意常数,显然我们可以使用换元积分法,令 $u = -1/2x^2$。
将 $e^{-1/2x^2}$ 替换为 $e^u$,将 $xdx$ 替换为 $-du$,我们有 \[ \int_{0}^{\infty} x\frac{1}{\sqrt{2\pi}}e^{-1/2x^2} dx = \int_{0}^{\infty} -\frac{1}{\sqrt{2\pi}}e^u du = -\frac{1}{\sqrt{2\pi}} \left[e^u\right]_{0}^{\infty} = -\frac{1}{\sqrt{2\pi}}(0-1) = \frac{1}{\sqrt{2\pi}}, \text{ 其中 } \left[e^u\right]_{0}^{\infty} \text{ 由 } x=0 \Rightarrow u=0 \text{ 和 } x=\infty \Rightarrow u=-\infty \text{ 确定。} \] \[ E[X | X > 0] = \frac{1}{\sqrt{2\pi}} \]
3.3 偏导数与多重积分
偏导数: \[ w=f(x,y) \quad\Rightarrow\quad \frac{\partial f}{\partial x}(x_0,y_0) =\lim_{\Delta x\to0} \frac{f(x_0+\Delta x,y_0)-f(x_0,y_0)}{\Delta x} =f_x. \] 二阶偏导数:\(\frac{\partial^2 f}{\partial x^2} = \frac{\partial}{\partial x}\left(\frac{\partial f}{\partial x}\right), \frac{\partial^2 f}{\partial x\partial y} = \frac{\partial}{\partial x}\left(\frac{\partial f}{\partial y}\right) = \frac{\partial}{\partial y}\left(\frac{\partial f}{\partial x}\right)\)
补充说明: 直观上,一阶偏导数描述函数沿某个方向的变化率;二阶偏导数则是该变化率本身的变化率。混合偏导数(如 \(\partial^2 f/(\partial x \partial y)\))在函数性质良好时与求导顺序无关。
一般链式法则:假设 \(w = f(x_1, x_2, \dots, x_m)\),且每个变量 \(x_1, x_2, \dots, x_m\) 都是变量 \(t_1, t_2, \dots, t_n\) 的函数。如果所有这些函数都有连续的一阶偏导数,则对于每个 \(i\)(\(1 \le i \le n\))有 \[ \frac{\partial w}{\partial t_i} = \frac{\partial w}{\partial x_1}\frac{\partial x_1}{\partial t_i} + \frac{\partial w}{\partial x_2}\frac{\partial x_2}{\partial t_i} + \dots + \frac{\partial w}{\partial x_m}\frac{\partial x_m}{\partial t_i}. \]
原书 PDF 第 57 页查看本页原始扫描图

将笛卡尔积分转换为极坐标积分
二维平面上的变量可以映射为极坐标:\(x = r \cos \theta\),\(y = r \sin \theta\)。在连续极坐标区域 \(R\) 上的积分可转换为 \[ \iint_R f(x, y) dx dy = \iint_R f(r \cos \theta, r \sin \theta) r dr d\theta. \]
补充说明: 极坐标下面积元素变为 \(r dr d\theta\),想象一下在极坐标中,一个小扇形微元的面积是弧长 \(r d\theta\) 乘以径向长度 \(dr\),所以多了一个因子 \(r\)。这与笛卡尔坐标中面积元素 \(dx dy\) 不同。
计算 \(\int_{-\infty}^{\infty} e^{-x^2/2} dx\)。解答:希望你恰好记得标准正态分布的概率密度函数是 \(f(x) = \frac{1}{\sqrt{2\pi}} e^{-x^2/2}\)。根据定义,我们有 \[ \int_{-\infty}^{\infty} f(x) dx = \int_{-\infty}^{\infty} \frac{1}{\sqrt{2\pi}} e^{-x^2/2} dx = 1 \implies \int_{-\infty}^{\infty} e^{-x^2/2} dx = \sqrt{2\pi}. \] 如果你忘记了标准正态分布的概率密度函数,或者题目明确要求证明 \(\int_{-\infty}^{\infty} \frac{1}{\sqrt{2\pi}} e^{-x^2/2} dx = 1\),就需要用极坐标积分来解决这个问题:
\[ \begin{aligned} \left(\int_{-\infty}^{\infty} e^{-x^2/2} dx\right) \left(\int_{-\infty}^{\infty} e^{-y^2/2} dy\right) &= \int_{-\infty}^{\infty} \int_{-\infty}^{\infty} e^{-x^2/2} e^{-y^2/2} dx dy \\ &= \int_{-\infty}^{\infty} \int_{-\infty}^{\infty} e^{-(x^2+y^2)/2} dx dy \\ &= \int_{0}^{\infty} \int_{0}^{2\pi} e^{-r^2/2} r dr d\theta \\ &= \int_{0}^{\infty} e^{-r^2/2} r \left(\int_{0}^{2\pi} d\theta\right) dr \\ &= \int_{0}^{\infty} e^{-r^2/2} r (2\pi) dr \\ &= 2\pi \int_{0}^{\infty} e^{-r^2/2} r dr \\ &= 2\pi \int_{0}^{\infty} e^{-u} du \qquad (u=r^2/2) \\ &= 2\pi \left[-e^{-u}\right]_0^{\infty} \\ &= 2\pi (0 - (-1)) \\ &= 2\pi \end{aligned} \] 由于 \(\left(\int_{-\infty}^{\infty} e^{-x^2/2} dx\right)^2 = \left(\int_{-\infty}^{\infty} e^{-y^2/2} dy\right)^2\),
我们有 \(\left(\int_{-\infty}^{\infty} e^{-x^2/2} dx\right)^2 = 2\pi \implies \int_{-\infty}^{\infty} e^{-x^2/2} dx = \sqrt{2\pi}\)。
3.4 重要的微积分方法
泰勒级数
一维泰勒级数将函数 \(f(x)\) 展开为关于点 \(x = x_0\) 处导数的级数和: \[ f(x) = f(x_0) + f'(x_0)(x-x_0) + \frac{f''(x_0)}{2!}(x-x_0)^2 + \dots + \frac{f^{(n)}(x_0)}{n!}(x-x_0)^n + \dots \]
原书 PDF 第 58 页查看本页原始扫描图

如果 \(x_0 = 0\),则 \(f(x) = f(0) + f'(0)x + \frac{f''(0)}{2!}x^2 + \dots + \frac{f^{(n)}(0)}{n!}x^n + \dots\) 泰勒级数常用于将函数表示为幂级数。例如,三个常见超越函数 \(e^x\), \(\sin x\) 和 \(\cos x\) 在 \(x_0 = 0\) 处的泰勒级数是: \[ e^x = \sum_{n=0}^{\infty} \frac{1}{n!} = 1 + \frac{x}{1!} + \frac{x^2}{2!} + \frac{x^3}{3!} + \dots \] \[ \sin x = \sum_{n=0}^{\infty} \frac{(-1)^n x^{2n+1}}{(2n+1)!} = x - \frac{x^3}{3!} + \frac{x^5}{5!} - \frac{x^7}{7!} + \dots \] \[ \cos x = \sum_{n=0}^{\infty} \frac{(-1)^n x^{2n}}{(2n)!} = 1 - \frac{x^2}{2!} + \frac{x^4}{4!} - \frac{x^6}{6!} + \dots \]
补充说明: 可以这样理解,泰勒级数就是用多项式来近似一个函数,在展开点附近,项数越多近似越精确。比如 \(\sin x\) 在 \(x=0\) 附近,第一项 \(x\) 给出斜率,加上 \(x^3/3!\) 来修正弯曲,以此类推。
泰勒级数也可以表示为 \(n\) 次泰勒多项式 \(T_n(x) = f(x_0) + f'(x_0)(x-x_0) + \frac{f''(x_0)}{2!}(x-x_0)^2 + \dots + \frac{f^{(n)}(x_0)}{n!}(x-x_0)^n\) 和余项 \(R_n(x)\) 的和:\(f(x) = T_n(x) + R_n(x)\)。
对于 \(x_0\) 和 \(x\) 之间的某个 \(\tilde{x}\),余项 \(R_n(x)\) 可以表示为: \[ R_n(x) = \frac{f^{(n+1)}(\tilde{x})}{(n+1)!}|x-x_0|^{n+1} \] 令 \(M\) 为 \(x_0\) 和 \(x\) 之间所有 \(\tilde{x}\) 的 \(|f^{(n+1)}(\tilde{x})|\) 的最大值,则我们得到约束: \[ |R_n(x)| \le \frac{M|x-x_0|^{n+1}}{(n+1)!} \]
补充说明: 余项就是多项式近似与真实函数之间的误差。这个误差受限于 \(|x-x_0|^{n+1}\) 的倍数,因此在展开点附近,误差很小。
A. \(i^i\) 是多少?解答: 这个问题使用欧拉公式 \(e^{i\theta} = \cos\theta + i\sin\theta\) 来解决,该公式可以通过泰勒级数证明。让我们来看一下证明。将泰勒级数应用于 \(e^{i\theta}\), \(\cos\theta\) 和 \(\sin\theta\),我们得到: \[ e^{i\theta} = 1 + \frac{i\theta}{1!} + \frac{(i\theta)^2}{2!} + \frac{(i\theta)^3}{3!} + \frac{(i\theta)^4}{4!} + \dots = 1 + i\frac{\theta}{1!} - \frac{\theta^2}{2!} - i\frac{\theta^3}{3!} + \frac{\theta^4}{4!} + i\frac{\theta^5}{5!} + \dots \] \[ \cos\theta = 1 - \frac{\theta^2}{2!} + \frac{\theta^4}{4!} - \frac{\theta^6}{6!} + \dots \] \[ \sin\theta = \theta - \frac{\theta^3}{3!} + \frac{\theta^5}{5!} - \frac{\theta^7}{7!} + \dots \implies i\sin\theta = i\frac{\theta}{1!} - i\frac{\theta^3}{3!} + i\frac{\theta^5}{5!} - i\frac{\theta^7}{7!} + \dots \]
原书 PDF 第 59 页查看本页原始扫描图

将这三个级数结合起来,可以清楚地看出 \(e^{i\theta} = \cos\theta + i\sin\theta\)。 当 \(\theta = \pi\) 时,方程变为 \(e^{i\pi} = \cos\pi + i\sin\pi = -1\)。当 \(\theta = \pi/2\) 时,方程变为 \(e^{i\pi/2} = \cos(\pi/2) + i\sin(\pi/2) = i\)。所以 \(\ln i = \ln(e^{i\pi/2}) = i\pi/2\)。因此,\(\ln(i^i) = i\ln i = i(i\pi/2) = -\pi/2 \Rightarrow i^i = e^{-\pi/2}\)。
B. 证明对于所有 \(x > -1\) 和所有整数 \(n \ge 2\),有 \((1+x)^n \ge 1+nx\)。
解答:令 \(f(x) = (1+x)^n\)。显然 \(1+nx\) 是 \(f(x)\) 在 \(x_0 = 0\) 处泰勒级数的前两项。所以我们可以考虑用泰勒级数来解决这道题。对于 \(x_0 = 0\),我们有 \((1+x)^n = 1\),\(\forall n \ge 2\)。\(f(x)\) 的一阶和二阶导数分别为 \(f'(x) = n(1+x)^{n-1}\) 和 \(f''(x) = n(n-1)(1+x)^{n-2}\)。
应用泰勒级数,我们有 \[ f(x) = f(x_0) + f'(x_0)(x-x_0) + \frac{f''(\tilde{x})}{2!}(x-x_0)^2 = f(0) + f'(0)x + \frac{f''(\tilde{x})}{2!}x^2 \] \[ = 1 + nx + n(n-1)(1+\tilde{x})^{n-2}x^2 \] 其中如果 \(x < 0\),则 \(x \le \tilde{x} \le 0\);如果 \(x > 0\),则 \(x \ge \tilde{x} \ge 0\)。由于 \(x > -1\) 且 \(n \ge 2\),我们有 \(n > 0\),\((n-1) > 0\),\((1+x)^{n-2} > 0\),\(x^2 \ge 0\)。
因此,\(n(n-1)(1+\tilde{x})^{n-2}x^2 \ge 0\),并且 \(f(x) = (1+x)^n \ge 1+nx\)。如果泰勒级数一时想不起来,题目中 \(n\) 是整数这一条件可能会提示你尝试数学归纳法。我们可以将问题重新表述为:对于每个整数 \(n \ge 2\),证明当 \(x > -1\) 时 \((1+x)^n \ge 1+nx\)。基础步骤:当 \(n=2\) 时,证明 \((1+x)^2 \ge 1+2x\) 对所有 \(x > -1\) 成立,这很容易证明,因为 \((1+x)^2 = 1+2x+x^2 \ge 1+2x\),对所有 \(x > -1\) 都成立。
归纳步骤:证明若当 \(n=k\) 时,对所有 \(x > -1\) 有 \((1+x)^n \geq 1+nx\),则该命题对 \(n=k+1\) 也成立:对所有 \(x > -1\) 有 \((1+x)^{k+1} \geq 1+(k+1)x\)。这一步骤同样直接。
脚注 3显然它们满足方程 \((e^{i\pi/2})^2 = i^2 = e^{i\pi} = -1\)。
原书 PDF 第 60 页查看本页原始扫描图

\((1+x)^{k+1} = (1+x)^k (1+x)\) \(\ge (1+kx)(1+x) = 1+(k+1)x+kx^2, \quad \forall x > -1\) \(\ge 1+(k+1)x\) 因此,当 \(x > -1\) 时,该命题对所有整数 \(n \ge 2\) 成立。
牛顿法
牛顿法,也称为牛顿-拉弗森法或牛顿-傅里叶法,是一种用于求解方程 \(f(x) = 0\) 的迭代过程。它从一个初始值 \(x_0\) 开始,并应用迭代步骤 \[ x_{n+1} = x_n - \frac{f(x_n)}{f'(x_n)} \] 来求解 \(f(x)=0\),前提是序列 \(x_1, x_2, \dots\) 收敛。脚注 4迭代方程来源于一阶泰勒级数: \(f(x_{n+1}) \approx f(x_n) + f'(x_n)(x_{n+1} - x_n) = 0 \Rightarrow x_{n+1} = x_n - \frac{f(x_n)}{f'(x_n)}\)。 牛顿法的收敛性并不总是得到保证,特别是当起始点远离正确解时。
为了使牛顿法收敛,初始点通常需要足够接近根;并且函数 \(f(x)\) 必须在根附近可微。当它收敛时,收敛速度是二次的,这意味着 \[ \frac{|x_{n+1} - x_f|}{(x_n - x_f)^2} \le \delta < 1, \] 其中 \(x_f\) 是方程 \(f(x)=0\) 的解。
A. 求解 \(x^2 = 37\) 精确到小数点后第三位。
解:令 \(f(x) = x^2 - 37\),原问题等价于求解 \(f(x)=0\)。取 \(x_0 = 6\) 作为自然的初始猜测。应用牛顿法,我们有 \[ x_1 = x_0 - \frac{f(x_0)}{f'(x_0)} = x_0 - \frac{x_0^2 - 37}{2x_0} = 6 - \frac{36-37}{2 \times 6} = 6.083. \] (\(6.083^2 = 37.00289\),非常接近 37。) 如果你不记得牛顿法,可以直接对函数 \(f(x) = \sqrt{x}\) 应用泰勒级数,其中 \(f'(x) = \frac{1}{2}x^{-1/2}\): \(f(37) \approx f(36) + f'(36)(37-36) = 6 + 1/12 = 6.083\)。
原书 PDF 第 61 页查看本页原始扫描图

或者,我们可以使用代数方法,因为很明显解应该略大于 6。我们有 \((6+y)^2 = 37 \Rightarrow y^2 + 12y - 1 = 0\)。如果忽略很小的 \(y^2\) 项,则 \(y = 0.083\),因此 \(x = 6+y = 6.083\)。
B. 你能解释一些求解 \(f(x)=0\) 的求根算法吗?假设 \(f(x)\) 是一个可微函数。
解:除了牛顿法,二分法和割线法是另外两种求根方法。脚注 5牛顿法也用于优化——包括多维优化问题——以寻找局部最小值或最大值。 二分法是一种直观的求根算法。它从两个初始值 \(a_0\) 和 \(b_0\) 开始,使得 \(f(a_0)<0\) 且 \(f(b_0)>0\)。由于 \(f(x)\) 是可微的,那么在 \(a_0\) 和 \(b_0\) 之间必然存在一个 \(x\) 使得 \(f(x)=0\)。在每一步,我们检查 \(f((a_n+b_n)/2)\) 的符号。如果 \(f((a_n+b_n)/2)<0\),我们设 \(b_{n+1}=b_n\) 且 \(a_{n+1}=(a_n+b_n)/2\);
如果 \(f((a_n+b_n)/2)>0\),我们设 \(a_{n+1}=a_n\) 且 \(b_{n+1}=(a_n+b_n)/2\);如果 \(f((a_n+b_n)/2)=0\),或其绝对值在允许误差范围内,则迭代停止,且 \(x=(a_n+b_n)/2\)。二分法线性收敛,即 \(\frac{x_{n+1}-x_f}{x_n-x_f} \leq \delta < 1\),这意味着它比牛顿法慢。但是,一旦找到一对 \(a_0/b_0\),收敛性就能得到保证。割线法从两个初始值 \(x_0, x_1\) 开始,并应用迭代步骤 \[ x_{n+1} = x_n - \frac{x_n - x_{n-1}}{f(x_n) - f(x_{n-1})} f(x_n) \] 它用线性近似 \(\frac{f(x_n) - f(x_{n-1})}{x_n - x_{n-1}}\) 替换了牛顿法中的 \(f'(x_n)\)。
与牛顿法相比,它不需要计算导数 \(f'(x_n)\),这在 \(f'(x)\) 难以计算时非常有价值。它的收敛速度是 \((1+\sqrt{5})/2\),这使得它比二分法快,但比牛顿法慢。与牛顿法类似,如果初始值不接近根,则不能保证收敛。
拉格朗日乘数法
拉格朗日乘数法是一种常用技术,用于在有一个或多个约束条件的情况下,寻找多元函数的局部最大值或最小值。脚注 6拉格朗日乘数法是 Karush-Kuhn-Tucker(KKT)条件的一个特例;KKT 条件给出了约束非线性优化问题最优解必须满足的必要条件。
原书 PDF 第 62 页查看本页原始扫描图

设 \(f(x_1, x_2, \dots, x_n)\) 是一个 \(n\) 个变量 \(x = (x_1, x_2, \dots, x_n)\) 的函数,其梯度向量为 \(\nabla f(x) = \left(\frac{\partial f}{\partial x_1}, \frac{\partial f}{\partial x_2}, \dots, \frac{\partial f}{\partial x_n}\right)\)。
在满足一组 \(k\) 个约束条件 \[ g_1(x_1, x_2, \dots, x_n) = 0, \quad g_2(x_1, x_2, \dots, x_n) = 0, \quad \dots, \quad g_k(x_1, x_2, \dots, x_n) = 0 \] 下,最大化或最小化 \(f(x)\) 的必要条件是 \(\nabla f(x) + \lambda_1 \nabla g_1(x) + \lambda_2 \nabla g_2(x) + \dots + \lambda_k \nabla g_k(x) = 0\),其中 \(\lambda_1, \dots, \lambda_k\) 被称为拉格朗日乘数。
从原点到平面 \(2x + 3y + 4z = 12\) 的距离是多少?
解:从原点到平面的距离 (\(D\)) 是原点和平面上各点之间的最小距离。从数学上讲,该问题可以表述为 \[ \min D^2 = f(x, y, z) = x^2 + y^2 + z^2 \] 满足约束条件 \[ g(x, y, z) = 2x + 3y + 4z - 12 = 0 \] 应用拉格朗日乘数法,我们有 \[ \begin{cases} \frac{\partial f}{\partial x} + \lambda \frac{\partial g}{\partial x} = 2x + 2\lambda = 0 \\ \frac{\partial f}{\partial y} + \lambda \frac{\partial g}{\partial y} = 2y + 3\lambda = 0 \\ \frac{\partial f}{\partial z} + \lambda \frac{\partial g}{\partial z} = 2z + 4\lambda = 0 \\ 2x + 3y + 4z - 12 = 0 \end{cases} \implies \begin{cases} \lambda = -24/29 \\ x = 24/29 \\ y = 36/29 \\ z = 48/29 \end{cases} \] 由此得到 \[ D = \sqrt{\left(\frac{24}{29}\right)^2 + \left(\frac{36}{29}\right)^2 + \left(\frac{48}{29}\right)^2} = \frac{12}{\sqrt{29}} \] 一般来说,对于方程为 \(ax + by + cz = d\) 的平面,到原点的距离为 \[ D = \frac{|d|}{\sqrt{a^2 + b^2 + c^2}} \]
3.5 常微分方程
在本节中,我们介绍面试中常见的四种典型微分方程模式。
原书 PDF 第 63 页查看本页原始扫描图

可分离微分方程
可分离微分方程的形式为 $\frac{dy}{dx} = g(x)h(y)$。由于它是可分离的,我们可以将原方程表示为 $\frac{dy}{h(y)} = g(x)dx$。对两边进行积分,我们得到解 $\int \frac{dy}{h(y)} = \int g(x)dx$。
A. 求解常微分方程 $y'+6xy=0, y(0)=1$
解: 令 $g(x)=-6x$ 和 $h(y)=y$,我们得到 $\frac{dy}{y} = -6xdx$。对原方程两边进行积分: \[ \int \frac{dy}{y} = \int -6xdx \Rightarrow \ln y = -3x^2 + c \Rightarrow y = e^{-3x^2+c} \] 其中 $c$ 是一个常数。 将初始条件 $y(0)=1$ 代入,我们得到 $c=0$ 且 $y=e^{-3x^2}$。
B. 求解常微分方程 \(y'=\frac{x-y}{x+y}\)脚注 7提示: 引入变量 \(z=x+y\)。
解: 令 \[ z=x+y,\qquad y=z-x,\qquad y'=\frac{dz}{dx}-1. \] 代回原方程: \[ \begin{aligned} \frac{dz}{dx}-1 &=\frac{x-(z-x)}{z}\\ &=\frac{2x-z}{z} =\frac{2x}{z}-1. \end{aligned} \] 两边同时加 \(1\),得到 \[ \frac{dz}{dx}=\frac{2x}{z}. \] 因此方程可以分离变量: \[ z\,dz=2x\,dx. \] 两边积分: \[ \frac{z^2}{2}=x^2+C_1 \quad\Longrightarrow\quad z^2=2x^2+C. \] 代回 \(z=x+y\),通解为 \[ (x+y)^2=2x^2+C, \] 等价地, \[ y^2+2xy-x^2=C. \] 可以直接求导验证:由 \((x+y)^2=2x^2+C\) 得 \[ 2(x+y)(1+y')=4x \quad\Longrightarrow\quad y'=\frac{2x}{x+y}-1=\frac{x-y}{x+y}. \]
一阶线性微分方程
一阶线性微分方程的标准形式为 \[ y'+P(x)y=Q(x). \] 取积分因子脚注 8积分因子中的任意非零乘法常数都可以省略,因为它只会把方程两边同时乘以同一个常数,不改变最终解。 \[ I(x)=e^{\int P(x)\,dx}. \] 因为 \(I'(x)=P(x)I(x)\),所以方程两边乘以 \(I(x)\) 后, \[ \begin{aligned} I(x)y'+I(x)P(x)y &=I(x)Q(x),\\ I(x)y'+I'(x)y &=I(x)Q(x),\\ \frac{d}{dx}\bigl(I(x)y\bigr) &=I(x)Q(x). \end{aligned} \]
原书 PDF 第 64 页查看本页原始扫描图

积分后可得一般解 \[ I(x)y=\int I(x)Q(x)\,dx+C, \qquad y=\frac{\int I(x)Q(x)\,dx+C}{I(x)}. \]
例:求解 \(y'+\frac1x y=\frac1{x^2}\),\(y(1)=1\),其中 \(x>0\)
这里 \[ P(x)=\frac1x,\qquad Q(x)=\frac1{x^2}. \] 积分因子为 \[ I(x)=e^{\int(1/x)\,dx}=e^{\ln x}=x. \] 原方程乘以 \(x\): \[ xy'+y=\frac1x \quad\Longrightarrow\quad (xy)'=\frac1x. \] 两边积分: \[ xy=\ln x+C, \qquad y=\frac{\ln x+C}{x}. \] 代入初始条件 \(y(1)=1\): \[ 1=C. \] 因此 \[ \boxed{y(x)=\frac{\ln x+1}{x}},\qquad x>0. \]
齐次线性方程
齐次线性方程是形如 $a(x)\frac{d^2 y}{dx^2} + b(x)\frac{dy}{dx} + c(x)y = 0$ 的二阶微分方程。很容易证明,如果 $y_1$ 和 $y_2$ 是齐次线性方程的两个线性无关解,那么任意 $y(x) = c_1 y_1(x) + c_2 y_2(x)$(其中 $c_1$ 和 $c_2$ 是任意常数)也是该齐次线性方程的解。 当 $a, b$ 和 $c$($a \neq 0$)是常数而非 $x$ 的函数时,齐次线性方程有闭式解: 设 $r_1$ 和 $r_2$ 为特征方程 $ar^2 + br + c = 0$ 的根,$^9$
原书 PDF 第 65 页查看本页原始扫描图

- 如果 $r_1$ 和 $r_2$ 是实数且 $r_1 \neq r_2$,则通解为 $y = c_1 e^{r_1 x} + c_2 e^{r_2 x}$;
- 如果 $r_1$ 和 $r_2$ 是实数且 $r_1 = r_2 = r$,则通解为 $y = c_1 e^{rx} + c_2 x e^{rx}$;
- 如果 $r_1$ 和 $r_2$ 是复数 $\alpha \pm i\beta$,则通解为 $y = e^{\alpha x} (c_1 \cos \beta x + c_2 \sin \beta x)$。
通过求通解的一阶和二阶导数,很容易验证这些通解确实满足齐次线性方程。 常微分方程 $y'' + y' + y = 0$ 的解是什么? 解: 在这个具体例子中,我们有 $a = b = c = 1$ 且 $b^2 - 4ac = -3 < 0$,所以我们得到复数根 $r = -1/2 \pm \sqrt{3}/2i$($\alpha = -1/2$,$\beta = \sqrt{3}/2$),因此该微分方程的通解为 \[ y = e^{\alpha x} (c_1 \cos \beta x + c_2 \sin \beta x) = e^{-1/2 x} (c_1 \cos(\sqrt{3}/2 x) + c_2 \sin(\sqrt{3}/2 x)). \]
非齐次线性方程
与齐次线性方程 $a \frac{d^2 y}{dx^2} + b \frac{dy}{dx} + cy = 0$ 不同,非齐次线性方程 $a \frac{d^2 y}{dx^2} + b \frac{dy}{dx} + cy = d(x)$ 没有闭式解。但是,如果我们能找到一个 $a \frac{d^2 y}{dx^2} + b \frac{dy}{dx} + cy = d(x)$ 的特解 $y_p(x)$,那么 $y = y_p(x) + y_g(x)$(其中 $y_g(x)$ 是齐次方程 $a \frac{d^2 y}{dx^2} + b \frac{dy}{dx} + cy = 0$ 的通解)就是非齐次方程 $a \frac{d^2 y}{dx^2} + b \frac{dy}{dx} + cy = d(x)$ 的通解。
脚注 9二次方程 $ar^2 + br + c = 0$ 的根由二次公式 $r = \frac{-b \pm \sqrt{b^2 - 4ac}}{2a}$ 给出。你应该记住这个公式,或者能通过 $(r + b/2a)^2 = (b^2 - 4ac)/4a^2$ 推导出它。
原书 PDF 第 66 页查看本页原始扫描图

尽管在一般情况下可能难以确定一个特定的解 $y_p(x)$,但在 $d(x)$ 是一个简单多项式的情况下,特解通常是同次数的多项式。常微分方程 $y'' + y' + y = 1$ 和 $y'' + y' + y = x$ 的解是什么?解: 在这些常微分方程中,我们再次有 $a=b=c=1$ 且 $b^2 - 4ac = -3 < 0$,因此我们得到复数根 $r = -1/2 \pm \sqrt{3}/2i$($\alpha = -1/2$, $\beta = \sqrt{3}/2$),通解为 \[ y = e^{-1/2x} (c_1 \cos(\sqrt{3}/2x) + c_2 \sin(\sqrt{3}/2x)). \] 对于 $y'' + y' + y = 1$,特解是什么?显然 $y=1$ 是一个特解。
因此,$y'' + y' + y = 1$ 的解是 \[ y = y_p(x) + y_g(x) = e^{-1/2x} (c_1 \cos(\sqrt{3}/2x) + c_2 \sin(\sqrt{3}/2x)) + 1. \] 为了找到 $y'' + y' + y = x$ 的特解,令 $y_p(x) = mx + n$,则我们有 $y'' + y' + y = 0 + m + (mx + n) = x \implies m=1, n=-1$。因此,特解是 $x-1$,而 $y'' + y' + y = x$ 的解是 \[ y = y_p(x) + y_g(x) = e^{-1/2x} (c_1 \cos(\sqrt{3}/2x) + c_2 \sin(\sqrt{3}/2x)) + (x-1). \]
3.6 线性代数
线性代数在应用量化金融中得到了广泛应用,因为它在统计学、优化、蒙特卡洛模拟、信号处理等方面发挥着作用。因此,它也是一个涵盖许多主题的综合性数学领域。在本节中,我们将讨论几个在统计学和数值方法中有重要应用的课题。
向量
一个 $n \times 1$(列)向量是一维数组。它可以表示 $R^n$(n 维)欧几里得空间中一个点的坐标。
原书 PDF 第 67 页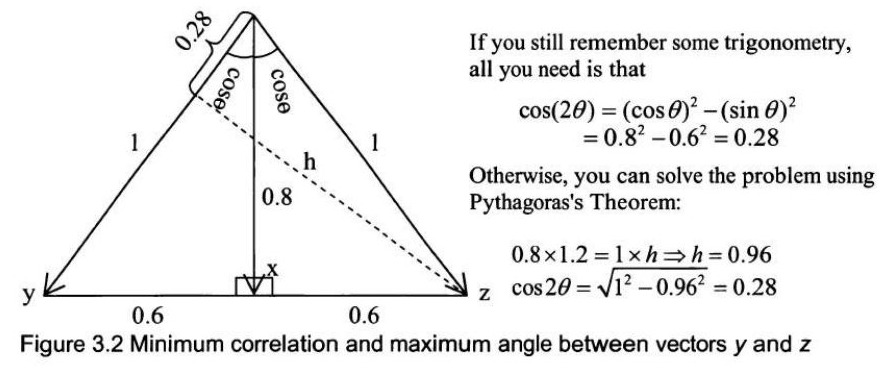
查看本页原始扫描图

内积/点积:两个 $R^n$ 向量 $x$ 和 $y$ 的内积(或点积)定义为
\[ \sum_{i=1}^{n} x_i y_i = x^T y \]
欧几里得范数:
\[ \|x\| = \sqrt{\sum_{i=1}^{n} x_i^2} = \sqrt{x^T x}; \|x-y\| = \sqrt{(x-y)^T (x-y)} \] 那么 $R^n$ 向量 $x$ 和 $y$ 之间的夹角 $\theta$ 满足 \[ \cos\theta = \frac{x^T y}{\|x\| \|y\|}. \] 如果 $x^T y = 0$,则 $x$ 和 $y$ 正交。两个随机变量的相关系数可以看作是它们在欧几里得空间中夹角的余弦值($\rho = \cos\theta$)。有三个随机变量 $x, y$ 和 $z$。$x$ 和 $y$ 之间的相关性是 0.8,$x$ 和 $z$ 之间的相关性也是 0.8。$y$ 和 $z$ 之间的最大和最小相关性是多少?解答: 我们可以将随机变量 x、y 和 z 视为向量。
设 θ 为 x 与 y 之间的夹角,则有 cosθ = ρ_{x,y} = 0.8。同理,x 与 z 之间的夹角也是 θ。要使 y 与 z 的相关系数最大,它们之间的夹角需要最小。此时,最小夹角为 0(当向量 y 和 z 方向相同时),相关系数为 1。要使相关系数最小,则需要 y 与 z 之间的夹角最大,如图 3.2 所示。如果你还记得一些三角学知识,只需要用到公式: \[ \cos(2\theta) = (\cos\theta)^2 - (\sin\theta)^2 \] \[ = 0.8^2 - 0.6^2 = 0.28 \] 否则,你也可以用勾股定理来求解: \[ 0.8 \times 1.2 = 1 \times h \Rightarrow h = 0.96 \] \[ \cos 2\theta = \sqrt{1^2 - 0.96^2} = 0.28 \]
原书 PDF 第 68 页查看本页原始扫描图

QR 分解
QR 分解:对于每个非奇异的 $n \times n$ 矩阵 $A$,存在唯一的正交矩阵 $Q$ 和上三角矩阵 $R$,其对角线元素为正,使得 $A=QR$脚注 10一个非奇异矩阵 $Q$ 被称为正交矩阵,如果 $Q^{-1}=Q^T$。当且仅当 $Q$ 的列(和行)在 $\mathbb{R}^n$ 中构成一个标准正交集时,$Q$ 是正交的。Gram-Schmidt 标准正交化过程(通常会改进以提高数值稳定性)常用于 QR 分解。如果你对 Gram-Schmidt 过程感兴趣,请参考线性代数教材。。
QR 分解常用于求解线性系统 $Ax=b$,当 $A$ 是非奇异矩阵时。由于 $Q$ 是正交矩阵,有 $Q^{-1}=Q^T$,所以 $QRx=b \Rightarrow Rx=Q^T b$。因为 $R$ 是上三角矩阵,我们可以从 $x_n$ 开始(方程为 $R_{n,n}x_n = (Q^T b)_n$),然后递归地计算所有 $x_i$,其中 $\forall i=n, n-1, \dots, 1$。
补充说明: 正交矩阵 $Q$ 的列向量在 $\mathbb{R}^n$ 空间中构成一组标准正交基,这意味着它们两两正交且长度为 1。这使得 $Q^T Q = I$(单位矩阵),因此 $Q^{-1} = Q^T$。上三角矩阵 $R$ 的主对角线以下元素全为零,这种结构使得求解 $Rx = Q^T b$ 时可以通过“回代法”轻松完成。
如果你的编程语言没有线性最小二乘回归的函数,你会如何设计一个算法来实现它?解答: 线性最小二乘回归可能是最广泛使用的统计分析方法。让我们通过矩阵来回顾一种标准的线性最小二乘回归求解方法。具有 $n$ 个观测值的简单线性回归可以表示为: \[ y_i = \beta_0 x_{i,0} + \beta_1 x_{i,1} + \dots + \beta_{p-1} x_{i,p-1} + \epsilon_i, \quad \forall i=1, \dots, n \] 其中 $x_{i,0}=1, \forall i$,是截距项,而 $x_{i,1}, \dots, x_{i,p-1}$ 是 $p-1$ 个外生回归变量。
线性最小二乘回归的目标是找到一组 $\beta = [\beta_0, \beta_1, \dots, \beta_{p-1}]^T$,使得 $\sum_{i=1}^n \epsilon_i^2$ 最小。让我们用矩阵形式表示线性回归: \[ Y = X\beta + \epsilon \] 其中 $Y = [Y_1, Y_2, \dots, Y_n]^T$ 和 $\epsilon = [\epsilon_1, \epsilon_2, \dots, \epsilon_n]^T$ 都是 $n \times 1$ 列向量;$X$ 是一个 $n \times p$ 矩阵,其中每一列代表一个回归变量(包括截距),每一行代表一个观测值。
那么问题就变成: \[ \min_{\beta} f(\beta) = \min_{\beta} \sum_{i=1}^n \epsilon_i^2 = \min_{\beta} (Y - X\beta)^T (Y - X\beta) \]
原书 PDF 第 69 页查看本页原始扫描图

为了最小化函数 $f(\beta)$,对 $f(\beta)$ 关于 $\beta$ 求一阶导数脚注 11要做到这一点,你确实需要一点关于矩阵导数的知识。一些重要的向量/矩阵导数公式是: \[ \frac{\partial a^T x}{\partial x} = a, \quad \frac{\partial Ax}{\partial x} = A, \quad \frac{\partial x^T Ax}{\partial x} = (A^T + A)x, \quad \frac{\partial^2 x^T Ax}{\partial x \partial x^T} = 2A \] \[ \frac{\partial (Ax+b)^T C(Dx+e)}{\partial x} = A^T C(Dx+e) + D^T C^T (Ax+b) \],得到 $f'(\beta)=2X^T(Y-X\hat{\beta})=0 \Rightarrow (X^TX)\hat{\beta}=X^TY$,其中 $(X^TX)$ 是一个 $p \times p$ 的对称矩阵,$X^TY$ 是一个 $p \times 1$ 的列向量。
令 $A=(X^TX)$ 且 $b=X^TY$,则问题变为 $A\hat{\beta}=b$,这可以用我们之前描述的 QR 分解来求解。或者,如果编程语言有矩阵求逆函数,我们可以直接计算 $\hat{\beta}$ 为 $\hat{\beta}=(X^TX)^{-1}X^TY$。脚注 12如果矩阵接近奇异或缩放比例很差,矩阵求逆会引入较大的数值误差。 既然我们讨论线性回归,值得指出线性最小二乘回归背后的假设(面试中常见的统计学问题):
- $Y$ 与 $X$ 之间的关系是线性的:$Y = X\beta + \epsilon$。
- $E[\epsilon_i]=0, \forall i=1, \dots, n$。
- $\text{var}(\epsilon_i)=\sigma^2, i=1, \dots, n$(方差恒定),且 $E[\epsilon_i\epsilon_j]=0, i \neq j$(误差不相关)。
- 无完全多重共线性:$\rho(x_i, x_j) \neq \pm 1, i \neq j$,其中 $\rho(x_i, x_j)$ 是回归变量 $x_i$ 和 $x_j$ 的相关系数。
- $\epsilon$ 和 $x_i$ 相互独立。
当然,在实践中,这些假设中的一些会被违反,此时简单的线性最小二乘回归就不再是最佳线性无偏估计量(BLUE)。许多计量经济学书籍用大量章节来讨论假设违反的影响及相应的补救措施。
行列式、特征值与特征向量
行列式:设 $A$ 是一个 $n \times n$ 矩阵,元素为 $\{A_{i,j}\}$,其中 $i, j = 1, \dots, n$。$A$ 的行列式定义为一个标量:
\[ \det(A) = \sum_{p} \text{sgn}(p) a_{1,p_1} a_{2,p_2} \cdots a_{n,p_n} \] 其中 $p=(p_1, p_2, \dots, p_n)$ 是 $(1, 2, \dots, n)$ 的任意排列;求和遍历所有 $n!$ 种可能的排列;且
原书 PDF 第 70 页查看本页原始扫描图

$\psi(p) = \begin{cases} 1, & \text{如果 } p \text{ 可以通过偶数次交换转换为自然顺序} \\ -1, & \text{如果 } p \text{ 可以通过奇数次交换转换为自然顺序} \end{cases}$ 例如,$2 \times 2$ 和 $3 \times 3$ 矩阵的行列式可以计算为 \[ \det \begin{bmatrix} a & b \\ c & d \end{bmatrix} = ad - bc, \quad \det \begin{bmatrix} a & b & c \\ d & e & f \\ g & h & i \end{bmatrix} = aei + bfg + cdh - ceg - afh - bdi.脚注 13这个 $3 \times 3$ 行列式的公式可以通过“对角线法则”记忆:从左上到右下三条主对角线乘积之和(aei, bfg, cdh)减去从右上到左下三条副对角线乘积之和(ceg, afh, bdi)。 \] 行列式的性质:$\det(A^T) = \det(A)$,$\det(AB) = \det(A)\det(B)$,$\det(A^{-1}) = \frac{1}{\det(A)}$。
特征值:设 $A$ 是一个 $n \times n$ 矩阵。如果存在 $\mathbb{R}^n$ 中的一个非零向量 $x$,使得 $Ax = \lambda x$,则实数 $\lambda$ 称为 $A$ 的一个特征值。每个满足该方程的非零向量 $x$ 称为对应于特征值 $\lambda$ 的特征向量。特征值和特征向量是常微分方程、马尔可夫链、主成分分析(PCA)等多种学科中的核心概念。行列式的重要性在于它与特征值/特征向量的关系。
脚注 14行列式为零意味着矩阵是奇异的(不可逆),这也意味着至少有一个特征值为零。 矩阵 $A - \lambda I$ 的行列式称为 $A$ 的特征多项式,其中 $I$ 是 $n \times n$ 单位矩阵(主对角线上为 1,其余为 0)。方程 $\det(A - \lambda I) = 0$ 称为 $A$ 的特征方程。$A$ 的特征值是其特征方程的实根。
利用特征方程,我们还可以证明 $\lambda_1 \lambda_2 \cdots \lambda_n = \det(A)$ 且 $\sum_{i=1}^n \lambda_i = \text{trace}(A) = \sum_{i=1}^n A_{i,i}$。当且仅当 $A$ 有线性无关的特征向量时,$A$ 是可对角化的。脚注 15可对角化意味着矩阵 $A$ 可以表示为 $A = X \Lambda X^{-1}$,其中 $\Lambda$ 是由特征值构成的对角矩阵。这极大地简化了矩阵的幂运算等操作。 设 $\lambda_1, \lambda_2, \dots, \lambda_n$ 为 $A$ 的特征值,$x_1, x_2, \dots, x_n$ 为对应的特征向量,且 $X = [x_1 | x_2 | \cdots | x_n]$,则 \[ X^{-1}AX = \begin{bmatrix} \lambda_1 & & & \\ & \lambda_2 & & \\ & & \ddots & \\ & & & \lambda_n \end{bmatrix} = D \implies A = XDX^{-1} \implies A^k = XD^k X^{-1}. \]
原书 PDF 第 71 页查看本页原始扫描图

2.1
如果矩阵 $A = \begin{bmatrix} 2 & 1 \\ 1 & 2 \end{bmatrix}$,那么 $A$ 的特征值和特征向量是什么?
解法:这是一个特征值和特征向量的简单例子。可以使用三种相关的方法求解: 方法 A: 直接应用特征值和特征向量的定义。令 $\lambda$ 为一个特征值,$x = \begin{bmatrix} x_1 \\ x_2 \end{bmatrix}$ 为其对应的特征向量。根据定义,我们有 \[ Ax = \begin{bmatrix} 2 & 1 \\ 1 & 2 \end{bmatrix} \begin{bmatrix} x_1 \\ x_2 \end{bmatrix} = \begin{bmatrix} 2x_1 + x_2 \\ x_1 + 2x_2 \end{bmatrix} = \lambda \begin{bmatrix} x_1 \\ x_2 \end{bmatrix} = \begin{bmatrix} \lambda x_1 \\ \lambda x_2 \end{bmatrix} \] 这给出了方程组: \[ \begin{cases} 2x_1 + x_2 = \lambda x_1 \\ x_1 + 2x_2 = \lambda x_2 \end{cases} \] 整理第一个方程,得到 $x_2 = (\lambda - 2)x_1$。
将其代入第二个方程: $x_1 + 2(\lambda - 2)x_1 = \lambda (\lambda - 2)x_1$ $x_1 (1 + 2\lambda - 4) = \lambda (\lambda - 2)x_1$ $x_1 (2\lambda - 3) = \lambda (\lambda - 2)x_1$ 或者,从方程组出发: \[ \begin{cases} (2-\lambda)x_1 + x_2 = 0 \\ x_1 + (2-\lambda)x_2 = 0 \end{cases} \] 由第一个方程,$x_2 = -(2-\lambda)x_1 = (\lambda-2)x_1$。
将其代入第二个方程: $x_1 + (2-\lambda)(\lambda-2)x_1 = 0$ $x_1 - (\lambda-2)^2 x_1 = 0$ $x_1 (1 - (\lambda-2)^2) = 0$ $x_1 (1 - (\lambda^2 - 4\lambda + 4)) = 0$ $x_1 (1 - \lambda^2 + 4\lambda - 4) = 0$ $x_1 (-\lambda^2 + 4\lambda - 3) = 0$ $-x_1 (\lambda^2 - 4\lambda + 3) = 0$ $-x_1 (\lambda - 1)(\lambda - 3) = 0$ 所以,要么 $\lambda = 3$,此时 $x_2 = (3-2)x_1 = x_1$(将 $\lambda = 3$ 代入方程 $2x_1 + x_2 = \lambda x_1$),对应的标准化特征向量为 $\begin{bmatrix} 1/\sqrt{2} \\ 1/\sqrt{2} \end{bmatrix}$;
要么 $\lambda = 1$,此时 $x_2 = (1-2)x_1 = -x_1$(将 $\lambda = 1$ 代入方程 $2x_1 + x_2 = \lambda x_1$),对应的标准化特征向量为 $\begin{bmatrix} 1/\sqrt{2} \\ -1/\sqrt{2} \end{bmatrix}$。方法 B: 使用方程 $\det(A - \lambda I) = 0$。
\[ \det(A - \lambda I) = \det \left( \begin{bmatrix} 2 & 1 \\ 1 & 2 \end{bmatrix} - \lambda \begin{bmatrix} 1 & 0 \\ 0 & 1 \end{bmatrix} \right) = \det \begin{pmatrix} 2-\lambda & 1 \\ 1 & 2-\lambda \end{pmatrix} = (2-\lambda)(2-\lambda) - 1 \times 1 = 0 \] 解此方程,有 $(2-\lambda)^2 - 1 = 0 \implies (2-\lambda)^2 = 1 \implies 2-\lambda = \pm 1$。如果 $2-\lambda = 1$,则 $\lambda = 1$。如果 $2-\lambda = -1$,则 $\lambda = 3$。
所以特征值是 $\lambda_1 = 1$ 和 $\lambda_2 = 3$。将特征值代入 $Ax = \lambda x$,即可得到对应的特征向量。方法 C: 使用方程 $\lambda_1 \cdot \lambda_2 \cdots \lambda_n = \det(A)$ 和 $\sum_{i=1}^n \lambda_i = \text{tr}(A) = \sum_{i=1}^n A_{i,i}$。对于 $2 \times 2$ 矩阵,有 $\lambda_1 \lambda_2 = \det(A)$ 和 $\lambda_1 + \lambda_2 = \text{tr}(A)$。
\[ \det(A) = 2 \times 2 - 1 \times 1 = 3 \] \[ \text{tr}(A) = 2 + 2 = 4 \] 因此有 \[ \begin{cases} \lambda_1 \times \lambda_2 = 3 \\ \lambda_1 + \lambda_2 = 4 \end{cases} \implies \begin{cases} \lambda_1 = 1 \\ \lambda_2 = 3 \end{cases} \] 同样,将特征值代入 $Ax = \lambda x$,即可得到对应的特征向量。
原书 PDF 第 72 页查看本页原始扫描图

半正定矩阵 / 正定矩阵
当 $A$ 是一个 $n \times n$ 的对称矩阵时,例如协方差矩阵和相关矩阵的情况,$A$ 的所有特征值都是实数。此外,属于 $A$ 的不同特征值的特征向量是正交的。 以下每个条件都是使对称矩阵 $A$ 成为半正定矩阵的充分必要条件:
- 对任意 $n \times 1$ 向量 $x$,有 $x^T Ax \ge 0$。
- $A$ 的所有特征值都是非负的。
- 所有左上角(或右下角)的子矩阵 $A_K$,$K=1, \dots, n$,其行列式非负。脚注 16矩阵 $A$ 为半正定的一个必要(但非充分)条件是 $A$ 没有负的对角元素。
补充说明: 我们用一个 $3\times3$ 的例子来解释“左上角子矩阵”。对于矩阵 $A = \begin{bmatrix} a_{11} & a_{12} & a_{13} \\ a_{21} & a_{22} & a_{23} \\ a_{31} & a_{32} & a_{33} \end{bmatrix}$,它的左上角子矩阵 $A_1 = \begin{bmatrix} a_{11} \end{bmatrix}$,$A_2 = \begin{bmatrix} a_{11} & a_{12} \\ a_{21} & a_{22} \end{bmatrix}$,$A_3 = A$。条件要求这些子矩阵的行列式都非负。
协方差矩阵/相关矩阵也必须是半正定的。如果随机变量之间没有完美的线性相关关系,那么协方差矩阵/相关矩阵也必须是正定的。以下每个条件都是使对称矩阵 $A$ 成为正定矩阵的充分必要条件:
- 对任意非零的 $n \times 1$ 向量 $x$,有 $x^T Ax > 0$。
- $A$ 的所有特征值都是正数。
- 所有左上角(或右下角)的子矩阵 $A_K$,$K=1, \dots, n$,其行列式为正。
有三个随机变量 $x$, $y$ 和 $z$。$x$ 与 $y$ 的相关系数为 0.8,$x$ 与 $z$ 的相关系数也为 0.8。$y$ 与 $z$ 之间的最大和最小相关系数是多少?
解法: 该问题可以利用相关矩阵的半正定性来求解。 设 $y$ 与 $z$ 的相关系数为 $\rho$,则 $x$, $y$ 和 $z$ 的相关矩阵为 \[ P = \begin{bmatrix} 1 & 0.8 & 0.8 \\ 0.8 & 1 & \rho \\ 0.8 & \rho & 1 \end{bmatrix} . \]
原书 PDF 第 73 页查看本页原始扫描图

\[ \det(P) = 1 \times \det \begin{pmatrix} 1 & \rho \\ \rho & 1 \end{pmatrix} - 0.8 \times \det \begin{pmatrix} 0.8 & 0.8 \\ \rho & 1 \end{pmatrix} + 0.8 \times \det \begin{pmatrix} 0.8 & 0.8 \\ 1 & \rho \end{pmatrix} \] \[ = (1-\rho^2) - 0.8 \times (0.8 - 0.8\rho) + 0.8 \times (0.8\rho - 0.8) = -0.28 + 1.28\rho - \rho^2 \ge 0 \] \[ \Rightarrow (\rho-1)(\rho-0.28) \le 0 \Rightarrow 0.28 \le \rho \le 1 \] 所以 $y$ 与 $z$ 之间的最大相关系数为 1,最小相关系数为 0.28。
LU 分解和 Cholesky 分解
设 \(A\) 是一个 \(n\times n\) 的非奇异矩阵。LU 分解把 \(A\) 写成下三角矩阵 \(L\) 与上三角矩阵 \(U\) 的乘积: \[ A=LU. \] 这一分解由高斯消元自然导出。脚注 17LU 分解在高斯消元法中自然出现。 实际数值计算中,为了避免主元为零或过小,通常还需要交换矩阵的行,写成 \[ PA=LU, \] 其中 \(P\) 是置换矩阵。
补充说明: 三角矩阵是指主对角线一侧的所有元素都为零的矩阵。例如,下三角矩阵 $L$ 的右上角全为零,上三角矩阵 $U$ 的左下角全为零。这种分解将复杂问题简化,类似于把一个大数拆分成两个更容易处理的因数之积。
LU 分解的作用:把一次困难求解变成两次三角求解
若 \(A=LU\),原方程 \(Ax=b\) 可写成 \(LUx=b\)。令 \(y=Ux\),先用前代法解 \(Ly=b\),再用回代法解 \(Ux=y\),即可得到 \(x\);这就是 LU 分解把一般方程组化为两次三角求解的作用,且更换右端向量 \(b\) 时无需重新分解 \(A\)。此外,\(\det(A)=\det(L)\det(U)=\left(\prod_{i=1}^{n}L_{ii}\right)\left(\prod_{i=1}^{n}U_{ii}\right)\);Doolittle 分解中的 \(L\) 为单位下三角矩阵,故 \(\det(A)=\prod_{i=1}^{n}U_{ii}\)。若使用主元交换 \(PA=LU\),则 \(\det(A)=\det(P)\det(L)\det(U)\),其中 \(\det(P)=\pm1\)。
Cholesky 分解与 LU 分解的关系
当 \(A\) 是对称正定矩阵时,可以利用其对称结构得到更紧凑的三角分解: \[ A=CC^T, \] 其中 \(C\) 是对角元素为正的下三角矩阵;等价地,也可写成 \[ A=R^TR,\qquad R=C^T. \] 这就是 Cholesky 分解。它与 LU 分解密切相关,但不能简单地说普通 LU 分解总满足 \(L=U^T\):通常还需要对对角缩放进行重新分配。Cholesky 分解专门针对对称正定矩阵,只需存储一个三角因子,计算量也约为一般 LU 分解的一半。在蒙特卡洛模拟中,Cholesky 分解常用于生成相关的随机变量,如下面的问题所示: 如果你拥有标准正态分布的随机数生成器,如何生成两个相关系数为 \(\rho\) 的 \(N(0,1)\)(标准正态分布)随机变量?
解法: 目标随机向量 \[ X=\begin{bmatrix}x_1\\x_2\end{bmatrix} \] 应具有协方差矩阵 \[ \Sigma= \begin{bmatrix} 1&\rho\\ \rho&1 \end{bmatrix}. \] 对 \(\Sigma\) 作 Cholesky 分解: \[ \Sigma=CC^T,\qquad C= \begin{bmatrix} 1&0\\ \rho&\sqrt{1-\rho^2} \end{bmatrix}. \] 可以直接验证 \[ CC^T= \begin{bmatrix} 1&\rho\\ \rho&\rho^2+(1-\rho^2) \end{bmatrix} = \begin{bmatrix} 1&\rho\\ \rho&1 \end{bmatrix} =\Sigma. \] 现在令 \[ Z=\begin{bmatrix}z_1\\z_2\end{bmatrix}, \qquad Z\sim N(0,I), \] 也就是 \(z_1,z_2\) 相互独立且都服从 \(N(0,1)\)。
定义 \[ X=CZ. \] 展开矩阵乘法便得到 \[ \begin{bmatrix}x_1\\x_2\end{bmatrix} = \begin{bmatrix} 1&0\\ \rho&\sqrt{1-\rho^2} \end{bmatrix} \begin{bmatrix}z_1\\z_2\end{bmatrix}, \] 即 \[ x_1=z_1,\qquad x_2=\rho z_1+\sqrt{1-\rho^2}\,z_2. \] Cholesky 因子 \(C\) 的作用至此就很清楚了:它把协方差为单位矩阵的独立随机向量 \(Z\),线性变换为协方差为 \(\Sigma\) 的相关随机向量 \(X\)。
因为 \[ \operatorname{Cov}(X) =\operatorname{Cov}(CZ) =C\operatorname{Cov}(Z)C^T =CIC^T =CC^T =\Sigma. \] 对于一般的 \(n\) 维多元正态分布 \(X\sim N(\mu,\Sigma)\),先求 \[ \Sigma=CC^T, \] 再生成 \(Z\sim N(0,I_n)\),最后令 \[ \boxed{X=\mu+CZ}. \] 这就是 Cholesky 分解在蒙特卡洛模拟中生成相关随机变量的标准用法。
原书 PDF 第 74 页查看本页原始扫描图

多元正态分布
多元正态分布 \(X = [X_1, X_2, \dots, X_n]^T \sim N(\mu, \Sigma)\),其中均值向量 \(\mu = [\mu_1, \mu_2, \dots, \mu_n]^T\),协方差矩阵 \(\Sigma\) 是一个 \(n \times n\) 的正定矩阵脚注 18多元正态分布的概率密度函数为 \[ f(x) = \frac{\exp\left(-\frac{1}{2}(x-\mu)^T \Sigma^{-1}(x-\mu)\right)}{(2\pi)^{n/2} \det(\Sigma)^{1/2}} \]。
我们可以将协方差矩阵 \(\Sigma\) 分解为 \(R^T R\),并生成 \(n\) 个独立的 \(N(0, 1)\) 随机变量 \(z_1, z_2, \dots, z_n\)。设向量 \(Z = [z_1, z_2, \dots, z_n]^T\),则 \(X\) 可以生成为 \(X = \mu + R^T Z\)。脚注 19一般地,如果 \(y = AX + b\),其中 \(A\) 和 \(b\) 是常数,则协方差矩阵 \(\Sigma_{yy} = A \Sigma_{xx} A^T\)。 或者,\(X\) 也可以使用另一种重要的矩阵分解方法——奇异值分解(SVD)来生成:对于任意 \(n \times p\) 矩阵 \(X\),存在一种分解形式 \(X = UDV^T\),其中 \(U\) 和 \(V\) 分别是 \(n \times p\) 和 \(p \times p\) 的正交矩阵,\(U\) 的列张成 \(X\) 的列空间,\(V\) 的列张成 \(X\) 的行空间;
\(D\) 是一个 \(p \times p\) 的对角矩阵,称为 \(X\) 的奇异值矩阵。对于一个正定协方差矩阵,我们有 \(V = U\) 且 \(\Sigma = UDU^T\)。此外,\(D\) 是由特征值 \(\lambda_1, \lambda_2, \dots, \lambda_n\) 构成的对角矩阵,而 \(U\) 是 \(n\) 个对应特征向量组成的矩阵。令 \(D^{1/2}\) 为对角元素是 \(\sqrt{\lambda_1}, \sqrt{\lambda_2}, \dots, \sqrt{\lambda_n}\) 的对角矩阵,则可以清楚地看出 \(D = (D^{1/2})^2 = (D^{1/2})(D^{1/2})^T\) 且 \(\Sigma = UD^{1/2}(UD^{1/2})^T\)。
同样,如果我们生成一个包含 \(n\) 个独立 \(N(0, 1)\) 随机变量的向量 \(Z = [z_1, z_2, \dots, z_n]^T\),则 \(X\) 可以生成为 \(X = \mu + (UD^{1/2})Z\)。
补充说明: 这里的关键是,协方差矩阵 \(\Sigma\) 是正定的,因此可以将其分解(如 Cholesky 分解或特征值分解中的 \(UD^{1/2}\))。然后通过线性变换 \(X = \mu + (\text{分解因子}) Z\),将独立的标准正态随机变量 \(Z\) 转换为具有所需相关结构的随机变量 \(X\)。公式 \(X = \mu + (UD^{1/2})Z\) 与 \(X = \mu + R^T Z\) 本质相同,只是分解方式不同:前者是特征值分解(或奇异值分解),后者是 Cholesky 分解。