第4章 概率论
原书 PDF 第 75 页原著:Xinfeng Zhou,A Practical Guide to Quantitative Finance Interviews(2008)。
本页由 GPT 视觉模型直接依据扫描页识别、翻译和公式排版。
查看本页原始扫描图

在大多数量化面试中,你很可能会遇到至少几个概率问题。概率论是量化金融各个方面的基础。因此,它已成为量化面试中的一个热门话题。尽管良好的直觉和逻辑可以帮助你解决许多概率问题,但透彻理解基础概率论将为你可能遇到的大多数问题提供清晰简洁的解决方案。此外,概率论在解释一些看似反直觉的结果方面极具价值。掌握一点知识,你会发现许多面试问题不过是改头换面的教科书习题。因此,我们专门用本章来回顾基础概率论,这不仅在面试中被广泛考察,也可能对你未来的职业生涯有所帮助。
脚注 1正如我在第3章所强调的,由于篇幅限制,本书不教授概率论或任何其他数学主题——这也不是我的目标。本书总结了经常被考察的知识,并展示了如何将其应用于广泛的真实面试问题。本章使用的知识在大多数概率论入门书籍中都有涵盖。如果你想重温某些主题,找一两本经典的概率论书籍总是有帮助的。我个人最喜欢的是 Sheldon Ross 的 First Course in Probability 以及 Dimitri P. Bertsekas 和 John N. Tsitsiklis 的 Introduction to Probability。 我们将把这些知识应用于真实的面试问题,以展示概率论的力量。
然而,知识的必要性绝不意味着低估直觉和逻辑的作用。恰恰相反,常识和良好的判断力对于分析和解决面试或现实生活中的问题始终至关重要。正如你在以下章节中将看到的,我们在第2章讨论的所有技巧在解决许多概率问题时仍然起着至关重要的作用。让我们来玩一玩概率游戏吧。
4.1 基本概率定义与集合运算
首先,让我们从概率论中使用的一些基本定义和符号开始。这些定义和符号在没有例子的情况下可能显得枯燥——我们稍后会给出例子——但它们对我们理解概率论至关重要。此外,它将为我们系统性地处理概率问题奠定坚实的基础。 结果 ($\omega$):一次实验或试验的结果。 样本空间/概率空间 ($\Omega$):一次实验所有可能结果的集合。
原书 PDF 第 76 页查看本页原始扫描图

$P(\omega)$:一个结果的概率($P(\omega) \ge 0, \forall \omega \in \Omega, \sum_{\omega \in \Omega} P(\omega) = 1$)。事件:一组结果的集合,是样本空间的一个子集。$P(A)$:事件 $A$ 的概率,$P(A) = \sum_{\omega \in A} P(\omega)$。$A \cup B$:并集 $A \cup B$ 是事件 $A$ 或事件 $B$(或两者)中的结果集合。$A \cap B$ 或 $AB$:交集 $A \cap B$(或 $AB$)是同时属于 $A$ 和 $B$ 的结果集合。$A^c$:$A$ 的补集,即事件“非 $A$”。互斥:$A \cap B = \Phi$,其中 $\Phi$ 是空集。
对于任何互斥事件 $E_1, E_2, \dots, E_N$,有 $P\left(\bigcup_{i=1}^N E_i\right) = \sum_{i=1}^N P(E_i)$。随机变量:一个将样本空间 ($\Omega$) 中的每个结果 ($\omega$) 映射到实数集合的函数。让我们用掷一个六面骰子来解释这些定义和符号。掷一次骰子有6种可能的结果(映射到一个随机变量):1、2、3、4、5或6。所以样本空间 $\Omega$ 是 $\{1, 2, 3, 4, 5, 6\}$,每个结果的概率是 $1/6$(假设骰子是公平的)。我们可以定义一个事件 $A$,表示结果是奇数,即 $A = \{1, 3, 5\}$,那么 $A$ 的补集是 $A^c = \{2, 4, 6\}$。显然 $P(A) = P(1) + P(3) + P(5) = 1/2$。令 $B$ 为结果大于3的事件:$B = \{4, 5, 6\}$。
那么并集是 $A \cup B = \{1, 3, 4, 5, 6\}$,交集是 $A \cap B = \{5\}$。事件 $A$ 的一个常用随机变量称为指示变量(一个二元虚拟变量),定义如下: \[ I_A = \begin{cases} 1, & \text{若 } x \in \{1, 3, 5\} \\ 0, & \text{若 } x \notin \{1, 3, 5\} \end{cases} \] 基本上,当 $A$ 发生时 $I_A = 1$,当 $A^c$ 发生时 $I_A = 0$。$I_A$ 的期望值是 $E[I_A] = P(A)$。现在,来看一些例子。
原书 PDF 第 77 页查看本页原始扫描图

抛硬币游戏
两个赌徒正在玩抛硬币游戏。赌徒 A 有 $n+1$ 枚均匀硬币;B 有 $n$ 枚均匀硬币。如果两人都抛掷他们所有的硬币,A 得到的正面数比 B 多的概率是多少?解:我们还没有涵盖概率论提供的所有强大工具。我们现在有什么?结果、事件、事件概率,当然还有我们的推理能力!那枚额外的硬币使 A 与 B 不同。如果我们从 A 那里拿走一枚硬币,A 和 B 将变得对称。毫不奇怪,对称性会给我们带来许多很好的性质。所以,让我们去掉 A 的最后一枚硬币,比较 A 的前 $n$ 枚硬币与 B 的 $n$ 枚硬币的正面数。有三种可能的结果: $E_1$:A 的 $n$ 枚硬币的正面数多于 B 的 $n$ 枚硬币;$E_2$:A 的 $n$ 枚硬币的正面数与 B 的 $n$ 枚硬币相等;$E_3$:A 的 $n$ 枚硬币的正面数少于 B 的 $n$ 枚硬币。根据对称性,A 正面数更多的概率等于 B 正面数更多的概率。
所以我们有 $P(E_1) = P(E_3)$。令 $P(E_1) = P(E_3) = x$,$P(E_2) = y$。由于 $\sum_{\omega \in \Omega} P(\omega) = 1$,我们有 $2x + y = 1$。对于事件 $E_1$,无论 A 的第 $(n+1)$ 枚硬币是哪一面,A 的正面数总是多于 B;对于事件 $E_3$,无论 A 的第 $(n+1)$ 枚硬币是哪一面,A 的正面数都不会多于 B。对于事件 $E_2$,A 的第 $(n+1)$ 枚硬币确实有影响。如果它是正面(概率为 0.5),它将使 A 的正面数多于 B。所以第 $(n+1)$ 枚硬币使 A 正面数多于 B 的概率增加了 $0.5y$,因此当 A 有 $(n+1)$ 枚硬币时,A 正面数多于 B 的总概率为 $x + 0.5y = x + 0.5(1 - 2x) = 0.5$。
补充说明: 这个问题的关键在于利用对称性简化分析。去掉 A 的一枚硬币后,比较前 $n$ 枚硬币的情况。然后单独考虑第 $(n+1)$ 枚硬币的影响,它只在双方前 $n$ 枚硬币正面数相等时(事件 $E_2$)才可能改变胜负。最终概率恰好是 0.5,与 $n$ 无关,这是一个有趣且反直觉的结果。
纸牌游戏
一家赌场提供一种简单的纸牌游戏。一副牌有 52 张,数值 2、3、4、5、6、7、8、9、10、J、Q、K、A 各 4 张。每次牌被彻底洗匀(因此每张牌被选中的概率相等)。你从牌堆中抽一张牌,庄家再从剩下的牌中抽另一张(不放回)。如果你的牌点数更大,你就赢;如果点数相等或你的点数更小,则庄家赢——就像所有其他赌场一样,庄家总是有更高的胜率。你获胜的概率是多少?
补充说明: 这里“点数”是指牌面数值的大小顺序,2最小,A最大。注意“不放回”意味着你抽走一张后,庄家从剩余的51张牌里抽。
脚注 2提示:如果我们比较 A 的前 \(n\) 枚硬币和 B 的 \(n\) 枚硬币中正面的数量,可能的结果(事件)是什么?通过使硬币数量相等,我们可以利用对称性。对于每个事件,如果 A 的最后一枚硬币是正面,会发生什么?如果是反面呢?
原书 PDF 第 78 页查看本页原始扫描图

解答:
解决这个问题的一种方法是考虑你手中牌的所有 13 种不同结果。牌的点数可以是 2、3、……、A,每种概率为 1/13。当点数为 2 时,获胜概率是 0/51;当点数为 3 时,获胜概率是 4/51(当庄家抽到 2 时);……;当点数为 A 时,获胜概率是 48/51(当庄家抽到 2、3、……或 K 时)。因此,你获胜的概率是 \[ \frac{1}{13} \times \left( \frac{0}{51} + \frac{4}{51} + \dots + \frac{48}{51} \right) = \frac{4}{13 \times 51} \times (0+1+\dots+12) = \frac{4}{13 \times 51} \times \frac{12 \times 13}{2} = \frac{8}{17}. \] 虽然这是一个直接的解法,并且巧妙地使用了整数序列的求和,但它并不是解决该问题最高效的方法。
如果你已经掌握了抛硬币问题的核心思想,你可以通过考虑三种不同的结果来求解: $E_1$:你的牌点数大于庄家的牌;$E_2$:你的牌点数等于庄家的牌;$E_3$:你的牌点数小于庄家的牌。同样根据对称性,$P(E_1) = P(E_3)$。所以我们只需要找出 $P(E_2)$,即两张牌点数相等的概率。假设你已经随机抽了一张牌。在剩下的 51 张牌中,只有 3 张牌与你的牌点数相同。因此,两张牌点数相等的概率是 3/51。所以,你获胜的概率是 $P(E_1) = (1 - P(E_2))/2 = (1 - 3/51)/2 = 8/17$。
醉酒的乘客
一行 100 名航空乘客正在排队登机。他们每人持有一张该航班上 100 个座位中某一个座位的机票。为方便起见,假设队伍中第 n 位乘客持有的机票是座位号 n。由于喝醉了,队伍中的第一个人随机选择一个座位(每个座位被选中的概率相等)。其他所有乘客都是清醒的,如果自己的座位空着,他们会去坐自己的座位;如果自己的座位已被占用,他们会在剩余的空位中随机选择一个。你是第 100 个人。你最终能坐到自己的座位(即 100 号座位)的概率是多少?
解答:
让我们考虑 1 号座位和 100 号座位。有两种可能的结果:
脚注 3提示:如果你正试图用复杂的条件概率来解决这个问题,请回去再想想。如果你决定从问题的简化版本开始,比如从两名乘客开始,然后通过归纳法增加乘客数量来展示规律,你可以更有效地解决问题。但这个问题比这要简单得多。专注于事件和对称性,你就会得到一个直观的答案。
原书 PDF 第 79 页查看本页原始扫描图

$E_1$:在 100 号座位被占之前,1 号座位被占了; $E_2$:在 1 号座位被占之前,100 号座位被占了。
补充说明: 这两个事件覆盖了所有可能性,因为最终要么是 1 号座位先被占,要么是 100 号座位先被占。它们不可能同时发生,因为第一个乘客只能选一个座位。
如果任何乘客在 1 号座位被占之前就占了 100 号座位,那么你肯定无法坐到自己的座位。但是,如果在 100 号座位被占之前有乘客占了 1 号座位,那么你最终一定能坐到自己的座位。由对称性可知,两种结果的概率均为 0.5。因此,你坐到自己的座位的概率是 50%。
补充说明: 为什么是0.5?关键点在于:对于任何一个在1号座位和100号座位之间做决定的“醉酒”乘客,他选择1号和100号的概率始终相等(因为都是随机选),所以这两种结果发生的可能性一样大。
如果这个过于简化的推理对你来说不够清晰,请考虑以下详细的解释:如果喝醉的乘客碰巧选了 1 号座位,那么显然所有其他乘客都会坐对座位。如果他选了 100 号座位,那么你将得不到你的座位。他选 1 号或 100 号座位的概率相等。否则,假设他选了第 n 个座位,其中 n 是 2 到 99 之间的一个数字。从 2 到 (n-1) 的每个人都会坐到自己的座位。这意味着第 n 位乘客本质上变成了新的“醉汉”,而他指定的座位是 1 号。如果他选了 1 号,那么所有剩余的乘客都会坐对座位。如果他选了 100 号,那么你将得不到你的座位。(他选 1 号或 100 号座位的概率再次相等。)否则,他只会让队伍中更靠后的另一位乘客成为指定的座位为 1 号的新“醉汉”,并且每个新的“醉汉”选择 1 号或 100 号座位的概率都相等。
由于在所有转折点上,“醉汉”选择 1 号或 100 号座位的概率都相等,由对称性可知,作为第 100 名乘客,你坐到 100 号座位的概率是 0.5。
圆上的 N 个点
在一个圆周上随机抽取 $N$ 个点,它们全部位于某个半圆内的概率是多少?脚注 4提示:考虑从点 $n$ 开始,可以沿顺时针方向在一个半圆内到达圆上所有其他点的事件,其中 $n \in \{1, \dots, N\}$。这些事件是互斥的吗? 解答:让我们从一个点开始,按顺时针方向将这些点标记为 1, 2, ..., $N$。所有从点 1 开始的顺时针半圆内包含其他 $N-1$ 个点(即点 2 到 N)的概率是 $1/2^{N-1}$。
类似地,从任意点 $i$ 开始的顺时针半圆包含所有其他 $N-1$ 个点的概率也是 $1/2^{N-1}$,其中 $i \in \{2, \dots, N\}$。
补充说明: 这里“从点 i 开始的顺时针半圆”是指,从点 i 出发,沿着顺时针方向走半个圆的弧长,这个弧覆盖的区域。
声明:所有其他 $N-1$ 个点都位于从点 $i$ 开始的顺时针半圆内的事件,对于 $i=1, 2, \dots, N$ 是互斥的。换句话说,如果从点 $i$ 开始沿着圆顺时针前进,我们依次遇到点 $i+1, i+2, \dots, N, 1, \dots, i-1$ 恰好都在半个圆内,那么从任何其他点 $j$ 开始,我们不可能在
原书 PDF 第 80 页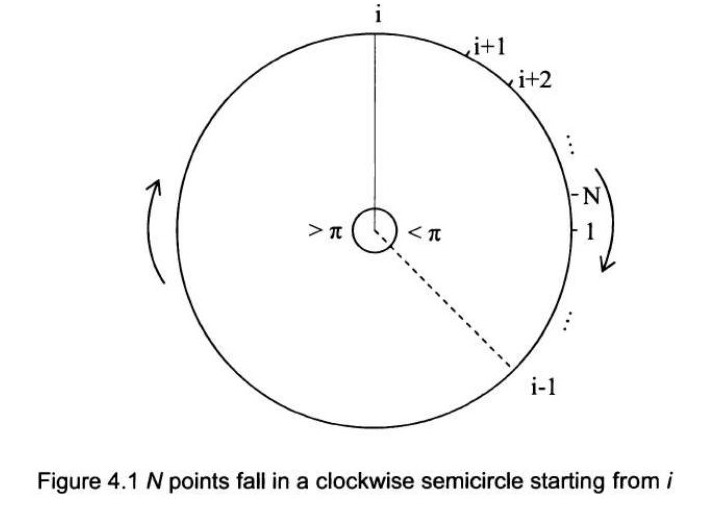
查看本页原始扫描图

顺时针半圆内包含所有其他点。图 4.1 清楚地展示了这一结论。如果从点 $i$ 开始并沿圆周顺时针前进,我们会依次遇到点 $i+1, i+2, \dots, N, 1, \dots, i-1$。在半个圆内,$i-1$ 和 $i$ 之间的顺时针弧长必须不小于半个圆。如果我们从任何其他点开始,为了顺时针到达所有其他点,弧长必须包含 $i-1$ 和 $i$ 之间的顺时针弧。因此,我们无法从任何其他点开始在顺时针半圆内到达所有点。所以,所有这些事件都是互斥的,我们有 \[ P\left(\bigcup_{i=1}^{N} E_{i}\right)=\sum_{i=1}^{N} P\left(E_{i}\right) \Rightarrow P\left(\bigcup_{i=1}^{N} E_{i}\right)=N \times 1/2^{N-1}=N / 2^{N-1} \]
补充说明: 因为事件互斥,所以它们并集的概率就等于各自概率的简单相加。
同样的论证可以扩展到任何长度小于半个圆的弧。如果弧长与圆周之比为 $x$($x \le 1/2$),那么所有 $N$ 个点都落入该弧的概率是 $N \times x^{N-1}$。
概率论中的许多问题,只需计算某个事件发生的不同方式的数量就能解决。研究计数问题的数学理论通常称为组合分析(或组合学)。本节将介绍组合分析的基础知识。 计数基本原理:设 \(S\) 为一个长度为 \(k\) 的序列集合。如果存在
原书 PDF 第 81 页查看本页原始扫描图

- 第一个条目有 \(n_1\) 种可能,
- 第二个条目有 \(n_2\) 种可能(对应每个第一个条目),
- 第三个条目有 \(n_3\) 种可能(对应每个第一和第二个条目的组合),
依此类推。那么总共有 \(n_1 \cdot n_2 \cdots n_k\) 种可能的结果。排列 (Permutation):对物体进行重新排列,形成不同的序列(即顺序很重要)。性质 (Property):\(n\) 个物体的不同排列共有 \(\frac{n!}{n_1! n_2! \cdots n_r!}\) 种,其中 \(n_1\) 个相同,\(n_2\) 个相同,\(\dots\),\(n_r\) 个相同。组合 (Combination):物体的无序集合(即顺序不重要)。性质 (Property):从 \(n\) 个不同物体中一次取 \(r\) 个的组合共有 \(\binom{n}{r} = \frac{n!}{(n-r)!r!}\) 种。
二项式定理 (Binomial theorem):\((x+y)^n = \sum_{k=0}^{n} \binom{n}{k} x^k y^{n-k}\) 容斥原理 (Inclusion-Exclusion Principle): \(P(E_1 \cup E_2) = P(E_1) + P(E_2) - P(E_1 E_2)\) \(P(E_1 \cup E_2 \cup E_3) = P(E_1) + P(E_2) + P(E_3) - P(E_1 E_2) - P(E_1 E_3) - P(E_2 E_3) + P(E_1 E_2 E_3)\) 并且更一般地, \[ P(E_1 \cup E_2 \cup \dots \cup E_N) = \sum_{i=1}^{N} P(E_i) - \sum_{i_1 < i_2} P(E_{i_1} E_{i_2}) + \dots + (-1)^{r+1} \sum_{i_1 < i_2 < \dots < i_r} P(E_{i_1} E_{i_2} \dots E_{i_r}) + \dots + (-1)^{N+1} P(E_1 E_2 \dots E_N) \] 其中 \(\sum_{i_1 < i_2 < \dots < i_r} P(E_{i_1} E_{i_2} \dots E_{i_r})\) 有 \(\binom{N}{r}\) 项。
扑克牌 (Poker hands)
扑克是一种纸牌游戏,每位玩家发 5 张牌。一副牌共有 52 张。每张牌都有一个点数并属于一个花色。有 13 种点数:2, 3, 4, 5, 6, 7, 8, 9, 10, J, Q, K, A,以及四种花色:黑桃 (spade)、梅花 (club)、红心 (heart)、方块 (diamond)。
| 点数 | 花色 | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | J | Q | K | A | ♠ | ♣ | ♥ | ♦ |
查看本页原始扫描图

拿到“四条”(五张牌中有四张点数相同)、“满堂红”(三张点数相同,另两张点数相同)和“两对”牌型的概率分别是多少?解答:五张牌的不同组合总数,就是从 52 张牌中选出 5 张的子集个数,因此总手牌数 = \( \binom{52}{5} \) = 2,598,960。四条牌型:首先,选择四张相同点数牌的点数,有 13 种选择。第 5 张牌可以是剩下的 48 张牌中的任意一张(点数有 12 种选择,每种点数有 4 种花色)。所以四条牌型的数量为 \( 13 \times 48 = 624 \)。满堂红牌型:依次选择三张相同点数牌的点数,有 13 种选择;这三张牌的花色组合,有 \( \binom{4}{3} \) 种选择;再选择两张相同点数牌的点数,有 12 种选择;这两张牌的花色组合,有 \( \binom{4}{2} \) 种选择。
所以满堂红牌型的数量为 \[ 13 \times \binom{4}{3} \times 12 \times \binom{4}{2} = 13 \times 4 \times 12 \times 6 = 3,744. \] 两对牌型:依次选择两对牌的点数,有 \( \binom{13}{2} \) 种选择;第一对牌的花色组合,有 \( \binom{4}{2} \) 种选择;第二对牌的花色组合,有 \( \binom{4}{2} \) 种选择;剩下的那张牌,有 44 种选择(52 减去 4×2,因为最后一张牌的点数不能与两对中的任何一对相同)。
所以两对牌型的数量为 \[ \binom{13}{2} \times \binom{4}{2} \times \binom{4}{2} \times 44 = 78 \times 6 \times 6 \times 44 = 123,552. \] 要计算每种牌型的概率,只需将每种牌型的数量除以总手牌数即可。
跳台阶的兔子
一只兔子坐在一个有 \( n \) 级台阶的楼梯底部。兔子每次只能向上跳 1 级或 2 级台阶。兔子有多少种不同的方式跳上楼梯顶部?脚注 5提示:考虑使用归纳法。在最后一步跳到第 \( n \) 级台阶之前,假设 \( n > 2 \),兔子可能位于第 \( (n-1) \) 级台阶或第 \( (n-2) \) 级台阶。
原书 PDF 第 83 页查看本页原始扫描图

解答:
我们从最简单的情况开始,然后使用归纳法求解任意级数台阶的问题。对于 \(n=1\),只有一种方式,所以 \(f(1)=1\)。对于 \(n=2\),可以一次跳 2 级,或者分两次各跳 1 级,所以 \(f(2)=2\)。对于任意 \(n>2\),最后一步总是有两种可能:要么跳 1 级,要么跳 2 级。如果是跳 1 级,那么兔子在到达第 \(n\) 级之前位于第 \((n-1)\) 级,它有 \(f(n-1)\) 种方式到达第 \((n-1)\) 级。如果是跳 2 级,那么兔子在到达第 \(n\) 级之前位于第 \((n-2)\) 级,它有 \(f(n-2)\) 种方式到达第 \((n-2)\) 级。因此我们得到 \(f(n)=f(n-2)+f(n-1)\)。利用这个递推关系,我们可以计算出 \(n=3, 4, \dots\) 时的 \(f(n)\)。
狡猾的海盗 2
在和平分完战利品(见第 2 章)后,海盗团队继续劫掠,并将队伍扩大到 11 名海盗。为了保护来之不易的财宝,他们决定将所有战利品放入一个保险箱。他们仍然奉行民主原则,规定只有多数人——任意多数人(\(\ge 6\))——一起才能打开保险箱。于是,他们请锁匠在保险箱上安装一定数量的锁。要取出财宝,必须打开每一把锁。每把锁可以有多个钥匙;但每个钥匙只能开一把锁。锁匠可以给每个海盗多把钥匙。 最少需要多少把锁?每个海盗必须携带多少把钥匙?脚注 7提示:6 名海盗的每个子群都应该拥有一个独特锁的相同钥匙,而其他 5 名海盗没有这个钥匙。
解答:
这个问题是组合分析在信息共享和密码学中应用的一个好例子。该问题的一般版本由 Adi Shamir 在 1979 年的论文《如何分享秘密》中阐述。我们从 11 名海盗中随机选出 5 名;必须有一把锁,这 5 名海盗都没有钥匙。然而,其他 6 名海盗中的任何一人都必须有这把锁的钥匙,因为任意 6 名海盗都能打开所有锁。换句话说,我们必须有一把“特殊”锁,被选出的 5 名海盗都没有钥匙,而其他 6 名海盗都有钥匙。这样的 5 人小组是随机选取的。因此,对于每一种 5 人组合,都必须有这样一把“特殊”锁。所需的最少锁数为
| \( \binom{11}{5} = \frac{11!}{5!6!} = 462 \) | 把锁。每把锁有 6 把钥匙,这些钥匙分配给一个唯一的 6 人小组。因此,每个海盗必须携带 |
| \( \frac{462 \times 6}{11} = 252 \) | 把钥匙。这确实需要在保险箱上安装很多锁,每个海盗也要携带很多钥匙。 |
查看本页原始扫描图

国际象棋锦标赛
一场国际象棋锦标赛有 $2^n$ 名选手,其技能水平为 $1 > 2 > \dots > 2^n$。比赛采用淘汰制,因此每轮比赛后只有胜者晋级下一轮。除决赛外,每轮比赛的对手都是随机抽签决定的。我们假设当两名选手在比赛中相遇时,技能水平更高的选手总是获胜。那么,选手 1 和选手 2 在决赛中相遇的概率是多少?脚注 8提示:考虑将选手分成两个 $2^{n-1}$ 人的子组。如果选手 1 和选手 2 在同一组会发生什么?或者不在同一组呢? 解法: 解决这个问题至少有兩種方法。标准方法基于条件概率使用乘法规则,而计数方法则高效得多。
(我们将在下一节详细讨论条件概率。) 我们先从条件概率方法开始,这种方法更容易理解。由于有 $2^n$ 名选手,锦标赛将进行 $n$ 轮(包括决赛)。对于第一轮,选手 $2, 3, \dots, 2^n$ 中的每一个成为选手 1 对手的概率都是 $\frac{1}{2^n-1}$,因此选手 1 和选手 2 在第一轮不相遇的概率为 \[ \frac{2^n-2}{2^n-1} = \frac{2 \times (2^{n-1}-1)}{2^n-1} \] 假设选手 1 和选手 2 在第一轮没有相遇,那么有 $2^{n-1}$ 名选手晋级第二轮,并且选手 1 和选手 2 在第二轮不相遇的条件概率为 \[ \frac{2^{n-1}-2}{2^{n-1}-1} = \frac{2 \times (2^{n-2}-1)}{2^{n-1}-1} \] 我们可以重复相同的过程,直到第 $(n-1)$ 轮,此时剩下 $2^2 (= 2^n / 2^{n-2})$ 名选手,并且选手 1 和选手 2 在第 $(n-1)$ 轮不相遇的条件概率为 \[ \frac{2^2-2}{2^2-1} = \frac{2 \times (2^2-1)}{2^2-1} \] 令 $E_1$ 表示选手 1 和选手 2 在第一轮不相遇的事件;
$E_2$ 表示选手 1 和选手 2 在第一轮和第二轮都不相遇的事件;$\dots$ $E_{n-1}$ 表示选手 1 和选手 2 在第 $1, 2, \dots, n-1$ 轮都不相遇的事件。应用乘法规则,我们得到 \[ P(1 \text{ 和 } 2 \text{ 在第 } n \text{ 局比赛中相遇}) = P(E_1) \times P(E_2 | E_1) \times \dots \times P(E_{n-1} | E_1 E_2 \dots E_{n-2}) \] \[ = \frac{2 \times (2^{n-1}-1)}{2^n-1} \times \frac{2 \times (2^{n-2}-1)}{2^{n-1}-1} \times \dots \times \frac{2 \times (2^2-1)}{2^3-1} = \frac{2^{n-1}}{2^n-1} \]
原书 PDF 第 85 页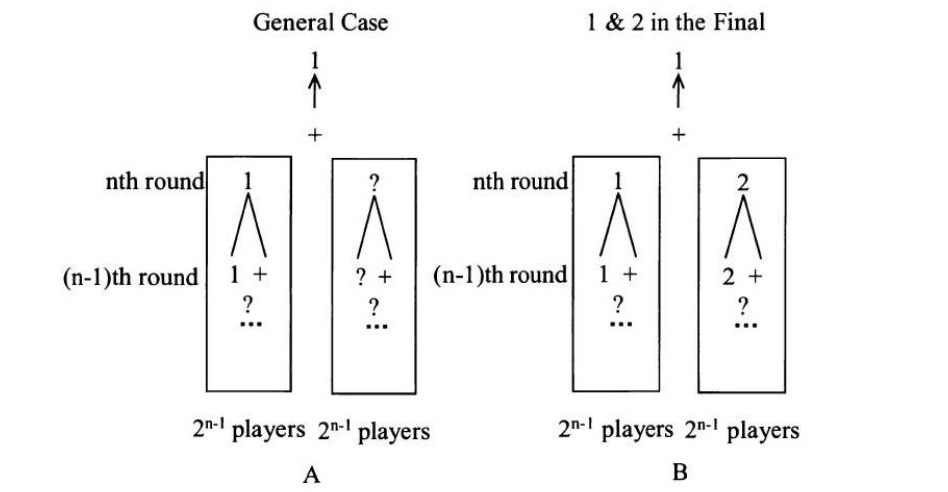
查看本页原始扫描图

现在让我们转向计数方法。图 4.2A 展示了决赛中发生情况的一般情形。选手 1 总是获胜,所以他会进入决赛。从图中可以明显看出,$2^n$ 名选手被分成两个 $2^{n-1}$ 名选手的小组,每个小组将有一名选手进入决赛。如图 4.2B 所示,选手 2 要进入决赛,他/她必须与选手 1 在不同的小组中。由于剩余的选手 2, 3, ..., $2^n$ 中,任何一个都可能是在与选手 1 同一小组的 $(2^{n-1}-1)$ 名选手之一,或者是在与选手 1 不同小组的 $2^{n-1}$ 名选手之一,因此选手 2 与选手 1 在不同小组并且选手 1 和选手 2 将在决赛中相遇的概率就是 $\frac{2^{n-1}}{2^n-1}$。显然,计数方法不仅提供了一个更简单的解决方案,而且对问题提供了更深入的见解。
求职信
你正在向 5 家公司发送求职申请:摩根士丹利(Morgan Stanley)、雷曼兄弟(Lehman Brothers)、瑞银集团(UBS)、高盛(Goldman Sachs)和美林证券(Merrill Lynch)。你桌上有 5 个信封,上面整齐地打印着这 5 家公司人员的姓名和地址。你甚至有 5 封为每家公司量身定制的求职信。你 3 岁的孩子试图帮忙,把每封求职信都塞进了相应的信封里。不幸的是,她随机地把信件放进了信封。
原书 PDF 第 86 页查看本页原始扫描图

而没有意识到这些信件是个人化的。那么,所有 5 封求职信都被寄错公司的概率是多少?脚注 9提示:其补事件是至少有一封信被寄到了正确的公司。
解法:
这个问题是容斥原理(Inclusion-Exclusion Principle)的一个经典例子。实际上,一个更一般的情况是 Ross 的教科书《概率论基础教程》(First Course in Probability)中的一个例子。令 $E_i, i=1, \dots, 5$ 表示第 $i$ 封信装对了信封的事件。那么 \[ P\left(\bigcup_{i=1}^5 E_i\right) \] 是至少有一封信装对信封的概率,而 \[ 1 - P\left(\bigcup_{i=1}^5 E_i\right) \] 是所有信都装错信封的概率。
$P\left(\bigcup_{i=1}^5 E_i\right)$ 可以使用容斥原理计算: \[ P\left(\bigcup_{i=1}^5 E_i\right) = \sum_{i=1}^5 P(E_i) - \sum_{i_1 < i_2} P(E_{i_1} E_{i_2}) + \dots + (-1)^6 P(E_1 E_2 \dots E_5) \] 显然,$P(E_i) = \frac{1}{5}, \forall i=1, \dots, 5$。所以 $ \sum_{i=1}^5 P(E_i) = 1 $。$P(E_{i_1} E_{i_2})$ 是信 $i_1$ 和信 $i_2$ 都装对信封的事件。信 $i_1$ 装对信封的概率是 $1/5$;在信 $i_1$ 装对信封的条件下,信 $i_2$ 装对信封的概率是 $1/4$(只剩下 4 个信封)。
所以 \[ P(E_{i_1} E_{i_2}) = \frac{1}{5} \times \frac{1}{5-1} = \frac{1}{5} \frac{(5-2)!}{5!} \] 在 $\sum_{i_1 < i_2} P(E_{i_1} E_{i_2})$ 中,$P(E_{i_1} E_{i_2})$ 的项数为 $ \binom{5}{2} = \frac{5!}{2!(5-2)!} $,因此我们有 \[ \sum_{i_1 < i_2} P(E_{i_1} E_{i_2}) = \frac{(5-2)!}{5!} \times \frac{5!}{2!(5-2)!} = \frac{1}{2!} \] 类似地,我们有 $ \sum_{i_1 < i_2 < i_3} P(E_{i_1} E_{i_2} E_{i_3}) = \frac{1}{3!} $,$ \sum_{i_1 < i_2 < i_3 < i_4} P(E_{i_1} E_{i_2} E_{i_3} E_{i_4}) = \frac{1}{4!} $ 以及 \[ P(E_1 E_2 \dots E_5) = \frac{1}{5!} \]
原书 PDF 第 87 页查看本页原始扫描图

$\therefore P\left(\bigcup_{i=1}^{5} E_{i}\right)=1-\frac{1}{2!}+\frac{1}{3!}-\frac{1}{4!}+\frac{1}{5!}=\frac{19}{30}$ 所以所有 5 封信都被寄错公司的概率是 $1-P\left(\bigcup_{i=1}^{5} E_{i}\right)=\frac{11}{30}$。
生日问题
一个班级需要有多少人,才能使至少两个人同一天生日的概率超过 1/2?(为简单起见,假设一年有 365 天。) 解法: 这个数字小得惊人:23 人。假设班级里有 $n$ 个人。在没有限制的情况下,每个人的生日有 365 种可能。计数基本原理告诉我们,总共有 $365^n$ 种可能的生日序列。我们想要找出那些没有重复生日的序列数量。对于第一个人,我们可以选择 365 天中的任何一天;但对于第二个人,只剩下 364 个选择,……,对于第 $r$ 个人,有 $365-r+1$ 个选择。所以对于 $n$ 个人,有 $365 \times 364 \times \dots \times (365-n+1)$ 种可能的序列,其中没有两个人的生日相同。我们需要满足 \[ \frac{365 \times 364 \times \dots \times (365-n+1)}{365^n} < 1/2 \] 才能使概率对我们有利。
满足条件的最小 $n$ 是 23。
第 100 位数字
在 $(1+\sqrt{2})^{3000}$ 的十进制表示中,小数点右边第 100 位数字是多少?解答: 如果你还没有从提示中想出解法,这里再给一个提示:当 $n=3000$ 时,$(1+\sqrt{2})^n + (1-\sqrt{2})^n$ 是一个整数。对 $(x+y)^n$ 应用二项式定理,我们有: \[ (1+\sqrt{2})^n = \sum_{k=0}^{n} \binom{n}{k} 1^{n-k} \sqrt{2}^k = \sum_{k=2j, 0 \le j \le \lfloor n/2 \rfloor} \binom{n}{k} 1^{n-k} \sqrt{2}^k + \sum_{k=2j+1, 0 \le j < \lfloor n/2 \rfloor} \binom{n}{k} 1^{n-k} \sqrt{2}^k \] 脚注 10提示:$(1+\sqrt{2})^2 + (1-\sqrt{2})^2 = 6$。当 $n$ 很大时,$(1-\sqrt{2})^{2n}$ 会怎么样?
原书 PDF 第 88 页查看本页原始扫描图

\[ (1-\sqrt{2})^n = \sum_{k=0}^{n} \binom{n}{k} 1^{n-k} (-\sqrt{2})^k = \sum_{k=2j, 0 \le j \le \lfloor n/2 \rfloor} \binom{n}{k} \sqrt{2}^k - \sum_{k=2j+1, 0 \le j < \lfloor n/2 \rfloor} \binom{n}{k} \sqrt{2}^k \] 因此,$(1+\sqrt{2})^n + (1-\sqrt{2})^n = 2 \sum_{k=2j, 0 \le j \le \lfloor n/2 \rfloor} \binom{n}{k} \sqrt{2}^k$,这个结果始终是一个整数。很容易看出 $0 < (1-\sqrt{2})^{3000} \ll 10^{-100}$。
所以 $(1+\sqrt{2})^n$ 的小数点后第 100 位数字一定是 9。
整数的立方
设 $x$ 是 $1$ 到 $10^{12}$ 之间的整数,$x$ 的立方以 11 结尾的概率是多少?脚注 11提示:$x^3$ 的最后两位数字只取决于 $x$ 的最后两位数字。 解答: 所有整数都可以表示为 $x = a+10b$,其中 $a$ 是 $x$ 的个位数。应用二项式定理,我们有 $x^3 = (a+10b)^3 = a^3 + 30a^2b + 300ab^2 + 1000b^3$。$x^3$ 的个位数仅取决于 $a^3$。所以 $a^3$ 的个位数字必须是 1。只有 $a=1$ 满足这个要求,且 $a^3=1$。因为 $a^3=1$,十位数只取决于 $30a^2b = 30b$。因此,我们必须让 $3b$ 的个位数是 1,这就要求 $b$ 的个位数字是 7。
于是,$x$ 的最后两位应该是 71,这在 $1$ 到 $10^{12}$ 之间的整数中出现的概率是 1%。
4.3 条件概率与贝叶斯公式
许多金融交易都是基于新信息(而且很可能是不完整信息)调整概率后的反应。条件概率无疑是量化面试中最热门的考试主题之一。因此,在本节中,我们将重点介绍基本的条件概率定义和定理。 条件概率 $P(A|B)$:如果 $P(B)>0$,那么 $P(A|B) = \frac{P(AB)}{P(B)}$ 表示在 $B$ 发生的结果中,同时也是 $A$ 发生的结果所占的比例。 乘法法则:$P(E_1 E_2 \cdots E_n) = P(E_1) P(E_2 | E_1) P(E_3 | E_1 E_2) \cdots P(E_n | E_1 \cdots E_{n-1})$。
原书 PDF 第 89 页查看本页原始扫描图

全概率公式:对于任何一组互斥事件 $\{F_i\}_{i=1,2,\dots,n}$,其并集为整个样本空间(即 $F_i \cap F_j = \Phi, \forall i \neq j; \bigcup_{i=1}^n F_i = \Omega$),我们有: \[ P(E) = P(EF_1) + P(EF_2) + \dots + P(EF_n) = \sum_{i=1}^n P(E|F_i)P(F_i) \] \[ = P(E|F_1)P(F_1) + P(E|F_2)P(F_2) + \dots + P(E|F_n)P(F_n) \] 独立事件:$P(EF) = P(E)P(F) \implies P(EF^c) = P(E)P(F^c)$。 独立性是对称的:$X$ 独立于 $Y$ 当且仅当 $Y$ 独立于 $X$。
贝叶斯公式:
\[ P(F_j|E) = \frac{P(E|F_j)P(F_j)}{\sum_{i=1}^n P(E|F_i)P(F_i)} \quad \text{其中 } F_i, i=1, \dots, n, \text{ 是互斥事件,且它们的并集为整个样本空间。} \] 正如以下示例将演示的,并非所有条件概率问题都有直观的解法。许多问题需要逻辑分析。
男孩和女孩
部分 A. 一家公司正在为至少有一个儿子的在职母亲举办晚宴。一位有两个孩子的母亲杰克逊女士被邀请了。两个孩子都是男孩的概率是多少?
解答: 两个孩子的样本空间由 $\Omega = \{(b,b), (b,g), (g,b), (g,g)\}$ 给出(例如,$(g,b)$ 表示大女儿是女孩,小儿子是男孩),每个结果的概率都相同。由于杰克逊女士被邀请,她至少有一个儿子。令 $B$ 为至少有一个孩子是男孩的事件,$A$ 为两个孩子都是男孩的事件。我们有: \[ P(A|B) = \frac{P(A \cap B)}{P(B)} = \frac{P(\{(b,b)\})}{P(\{(b,b), (b,g), (g,b)\})} = \frac{1/4}{3/4} = \frac{1}{3}. \]
部分 B. 你的新同事帕克女士已知有两个孩子。如果你看到她带着其中一个孩子散步,而那个孩子是男孩,那么两个孩子都是男孩的概率是多少?
原书 PDF 第 90 页查看本页原始扫描图

解答: 另一个孩子是男孩或女孩的概率是相等的(独立于你看到的那个男孩),所以两个孩子都是男孩的概率是 1/2。请注意部分 A 和部分 B 之间的细微差别。在部分 A,问题本质上是问,已知两个孩子中至少有一个是男孩,那么两个孩子都是男孩的条件概率是多少。部分 B 问的是,已知一个孩子是男孩,那么另一个孩子也是男孩的条件概率是多少。对于这两部分,我们都需要假设每个孩子是男孩或女孩的概率是相等的。全是女孩的世界? 在一个原始社会,每对夫妇都希望生一个女孩。他们所生的每个孩子是女孩的概率是 50%,并且孩子的性别是相互独立的。如果每对夫妇坚持继续生育,直到生下女孩为止,并且一旦生下女孩就停止生育,那么这个社会中女孩的比例最终会如何变化?解答: 令人惊讶的是,许多面试者——包括许多学习过概率的人——都存在一种误解,认为女孩的比例会增加。不要让“希望”这个词和错误的直觉误导你。
婴儿女孩的比例是由自然决定的,或者至少是由 $X$ 和 $Y$ 染色体决定的,而不是由夫妇的偏好决定的。你只需要关注关键信息:50% 和独立性。每个新生儿是男孩或女孩的概率是相等的,与任何其他孩子的性别无关。因此,出生的女孩比例始终是 50%,社会中的女孩比例将稳定在 50%。不公平的硬币 给你 1000 枚硬币。其中,1 枚硬币两面都是正面。其余 999 枚是公平的硬币。你随机选择一枚硬币并抛掷 10 次。每次抛掷的结果都是正面。你选择的硬币是不公平的硬币的概率是多少?解答: 这是一个经典的条件概率问题,使用了贝叶斯定理。设 $A$ 为所选硬币是不公平的硬币的事件,则 $A^c$ 为所选硬币是公平的硬币的事件。设 $B$ 为所有十次抛掷都出现正面的事件。
根据贝叶斯定理,我们有: \[ P(A|B) = \frac{P(B|A)P(A)}{P(B)} = \frac{P(B|A)P(A)}{P(B|A)P(A) + P(B|A^c)P(A^c)} \] 先验概率为 $P(A) = 1/1000$ 和 $P(A^c) = 999/1000$。如果硬币是不公平的,它总是出现正面,所以 $P(B|A) = 1$。如果硬币是公平的,每次出现正面的概率是 $1/2$。
原书 PDF 第 91 页查看本页原始扫描图

所以 $P(B|A^c) = (1/2)^{10} = 1/1024$。代入所有可用信息,我们得到答案: \[ P(A|B) = \frac{P(B|A)P(A)}{P(B|A)P(A) + P(B|A^c)P(A^c)} = \frac{1/1000 \times 1}{1/1000 \times 1 + 999/1000 \times 1/1024} \approx 0.5. \] 从一枚不公平的硬币中得到公平的概率 如果你有一枚不公平的硬币,它可能偏向正面或反面,且概率未知,你能用这枚硬币产生均等的机会吗?解答: 与公平的硬币不同,我们显然不能通过一次抛掷来产生均等的机会。那么使用两次抛掷呢?设 $p_H$ 为硬币出现正面的概率,设 $p_T$ 为硬币出现反面的概率($p_H + p_T = 1$)。考虑两次独立抛掷。
我们有四种可能的结果:HH、HT、TH 和 TT,其概率分别为 $P(HH) = p_H p_H$,$P(HT) = p_H p_T$,$P(TH) = p_T p_H$,以及 $P(TT) = p_T p_T$。所以我们有 $P(HT) = P(TH)$。通过将 HT 指定为获胜,TH 指定为失败,我们可以产生均等的机会。脚注 12我应该指出,这种简单的方法不是最高效的方法,因为我忽略了 HH 和 TT 的情况。当硬币的偏倚很高时(一面比另一面出现的可能性大得多),该方法可能需要多次运行才能产生一个有用的结果。有关提高效率的更复杂算法,请参阅 Quentin F. Stout 和 Bette L. Warren 的论文《Tree Algorithms for Unbiased Coin Tossing with a Biased Coin》,发表于《Annals of Probability》12 卷(1984 年),第 212-222 页。 飞镖游戏 杰森向飞镖靶投掷两枚飞镖,目标是中心。
第二枚飞镖比第一枚飞镖离中心更远。如果杰森投掷第三枚飞镖瞄准中心,第三次投掷比第一次投掷离中心更远的概率是多少?假设杰森的技巧水平恒定。解答: 一个标准的答案是直接通过列举所有可能的结果来应用条件概率。如果我们对三枚飞镖的结果从最好($A$)到最差($C$)进行排序,有 6 种等可能的结果:
原书 PDF 第 92 页查看本页原始扫描图

| 结果 | 1 | 2 | 3 | 4 | 5 | 6 |
| 第一次投掷 | A | B | A | C | B | C |
| 第二次投掷 | B | A | C | A | C | B |
| 第三次投掷 | C | C | B | B | A | A |
从前两次投掷获得的信息消除了结果 2、4 和 6。在结果 1、3 和 5 的条件下,第三次投掷比第一次投掷更差的结果是结果 1 和 3。因此,第三次投掷比第一次投掷离中心更远的可能性是 2/3。这种方法当然是合理的。然而,它并不是一种高效的方法。当飞镖数量很少时,我们可以轻松地枚举所有结果。如果这是原始问题的一个更复杂的版本呢: 杰森投掷 $n$($n \geq 5$)枚飞镖,目标是中心。每一次后续投掷都比第一次投掷离中心更远。如果杰森投掷第 $(n+1)$ 枚飞镖,它也比他的第一次投掷离中心更远的可能性是多少?这个问题等价于一个简单的问题:第 \((n+1)\) 次投掷不是所有 \((n+1)\) 次投掷中最好的一次,其可能性是多少?
由于第一次投掷是前 \(n\) 次投掷中最好的一次,我实际上是在说:事件“第 \((n+1)\) 次投掷是所有 \((n+1)\) 次投掷中最好的一次”(我们称之为 \(A_{n+1}\))与事件“第一次投掷是前 \(n\) 次投掷中最好的一次”(我们称之为 \(A_n\))是独立的。事实上,\(A_{n+1}\) 与前 \(n\) 次投掷的顺序是独立的。这两个事件真的独立吗?答案是响亮的“是”。如果你不清楚 \(A_{n+1}\) 与前 \(n\) 次投掷的顺序是独立的,让我们从另一个角度来看:前 \(n\) 次投掷的顺序与 \(A_{n+1}\) 是独立的。这个说法当然是显而易见的。但独立性是对称的!由于 \(A_{n+1}\) 的可能性是 \(1/(n+1)\),第 \((n+1)\) 次投掷不是最好的一次的可能性是 \(n/(n+1)\)。
¹³ 对于原始版本,投掷三支飞镖是独立的,它们各自有 \(1/3\) 的可能性是最好的一次投掷。只要第三次投掷不是最好的一次,它就会比第一次投掷差。因此答案是 \(2/3\)。
生日排队问题
在一家电影院,一位异想天开的经理宣布,她将免费赠送一张票给排在队伍中第一个生日与已经购票的人相同的人。你有机会选择队伍中的任何位置。假设你不知道其他人的生日,并且所有生日在一年中随机分布(假设一年有 365 天),那么队伍中的哪个位置能让你获得免费票的概率最大?¹⁴
解答:
如果你已经解决了在 \(n\) 人群体中没有两人同生日的问题,那么这个新问题只是一个小扩展。假设你选择成为队伍中的第 \(n\) 个人。为了让你获得免费票,队伍中的前 \(n-1\) 个人必须生日全部不同,并且你的生日需要与这 \(n-1\) 个人中的某一人相同。\[ p(n) = p(\text{前 } n-1 \text{ 人没有相同生日}) \times p(\text{你的生日出现在那 } n-1 \text{ 个生日中}) \] \[ = \frac{365 \times 364 \times \cdots \times (365-n+2)}{365^{n-1}} \times \frac{n-1}{365} \] 直观上可以认为,当 \(n\) 较小时,增加 \(n\) 会增加你获得免费票的机会,因为 \(p(\text{你的生日出现在那 } n-1 \text{ 个生日中})\) 的增加比 \(p(\text{前 } n-1 \text{ 人生日互不相同})\) 的减少更显著。
所以当 \(n\) 较小时,我们有 \(P(n) > P(n-1)\)。随着 \(n\) 增加,\(p(\text{前 } n-1 \text{ 人生日互不相同})\) 的负面影响逐渐追赶上来,在某个点我们会得到 \(P(n+1) < P(n)\)。所以我们需要找到一个满足 \(P(n) > P(n-1)\) 且 \(P(n) > P(n+1)\) 的 \(n\)。
\[ P(n-1) = \frac{365}{365} \times \frac{364}{365} \times \cdots \times \frac{365-(n-3)}{365} \times \frac{n-2}{365} \] \[ P(n) = \frac{365}{365} \times \frac{364}{365} \times \cdots \times \frac{365-(n-2)}{365} \times \frac{n-1}{365} \] \[ P(n+1) = \frac{365}{365} \times \frac{364}{365} \times \cdots \times \frac{365-(n-2)}{365} \times \frac{365-(n-1)}{365} \times \frac{n}{365} \] 因此, \[ P(n) > P(n-1) \Rightarrow \frac{365-(n-2)}{365} \times \frac{n-1}{365} > \frac{n-2}{365} \] \[ P(n) > P(n+1) \Rightarrow \frac{n-1}{365} > \frac{365-(n-1)}{365} \times \frac{n}{365} \] \[ \left. \begin{array}{l} \Rightarrow n^2 - 3n - 363 < 0 \\ \Rightarrow n^2 - n - 365 > 0 \end{array} \right\} \Rightarrow n=20 \] 你应该成为队伍中的第 20 个人。
原书 PDF 第 93 页补充说明: 这个问题的关键是找到概率的最大值。我们通过比较相邻位置的概率大小,找到了使概率达到峰值的那个位置。最终的解 \(n=20\) 表示,当你站在第 20 位时,获得免费票的可能性最大。
补充说明: 更直观的解释是,如果你站在第 20 位,那么前 19 人的生日互不相同的概率仍然较高,而你的生日与其中一人相同的可能性也足够大,二者乘积达到最大。
查看本页原始扫描图

……(此处为英文书名,保留原样)……
原书 PDF 第 94 页查看本页原始扫描图

骰子顺序问题
我们依次投掷三个骰子。得到的点数严格递增的概率是多少?¹⁵ 解答: 要得到严格递增的三个点数,首先这三个点数必须各不相同。在三个点数各不相同的前提下,严格递增的概率就是 \(1/3! = 1/6\)(即所有可能排列中特定的那一种序列)。所以我们有: \[ P = P(\text{三次投掷点数各不相同}) \times P(\text{递增顺序}\mid 3\text{ 个不同的点数}) \] \[ = (1 \times \frac{5}{6} \times \frac{4}{6}) \times \frac{1}{6} = \frac{5}{54} \]
蒙提霍尔问题
蒙提霍尔问题是一个概率谜题,源自一个古老的美国电视节目 Let's Make a Deal。该问题以主持人的名字命名。假设你现在正在参加这个节目,面前有三扇门。一扇门后面有一辆汽车;另外两扇门后面是山羊。你事先不知道每扇门后面是什么。你选择一扇门并宣布你的选择。就在你选择门之后,蒙提打开了另外两扇门中他知道后面有山羊的那一扇。然后他给你一个选择:坚持你最初的选择,或者换到第三扇门。你应该换吗?如果你换门,赢得汽车的概率是多少?解答: 如果你不换门,你是否赢得汽车与蒙提向你展示山羊的行为无关,因此你获胜的概率是 \(1/3\)。如果你换门呢?许多人会争辩说,由于蒙提交代了一扇有山羊的门之后只剩下两扇门,获胜的概率是 \(1/2\)。但这个论证正确吗?如果你从不同的角度看待这个问题,答案就会变得清晰。
使用换门策略,你赢得汽车当且仅当你最初选到的是有山羊的门,这个概率是 \(2/3\)(你选到有山羊的门,蒙提展示另一扇有山羊的门,所以换到的门后面一定是汽车)。如果你最初选到了有汽车的门,这个概率是 \(1/3\),那么换门就会输。所以换门策略获胜的概率实际上是 \(2/3\)。
原书 PDF 第 95 页补充说明: 更直观的理解是:最初选择时,你选中山羊的概率是 \(2/3\)。一旦你选中山羊,蒙提必然会打开另一扇有山羊的门,此时换门必定得到汽车。因此,换门的获胜概率等于你最初选中山羊的概率,即 \(2/3\)。
查看本页原始扫描图

变形虫种群问题
池塘里有一只变形虫。每过一分钟,这只变形虫可能会死亡、保持不变、分裂成两只或分裂成三只,每种情况的概率相等。它所有的后代(如果有的话)都会有相同的行为(并且与其他变形虫独立)。变形虫种群灭绝的概率是多少?解答: 这只是另一个标准的条件概率问题,一旦你意识到我们需要根据变形虫一分钟后发生的情况来推导概率。设 \(P(E)\) 为变形虫种群灭绝的概率,并应用全概率定律,条件为变形虫在一分钟后发生的情况: \[P(E) = P(E|F_1)P(F_1) + P(E|F_2)P(F_2) + \dots + P(E|F_n)P(F_n)\] 对于原始变形虫,如问题所述,有四种可能的互斥事件,每种事件的概率为 \(1/4\)。我们用 \(F_1\) 表示变形虫死亡的事件;\(F_2\) 表示变形虫保持不变的事件;\(F_3\) 表示变形虫分裂成两只的事件;\(F_4\) 表示变形虫分裂成三只的事件。
对于事件 \(F_1\),\(P(E|F_1) = 1\),因为没有变形虫存活。对于事件 \(F_2\),\(P(E|F_2) = P(E)\),因为状态与开始时相同。对于事件 \(F_3\),有两只变形虫;它们各自的行为与原始变形虫相同。变形虫总种群灭绝的唯一条件是两只变形虫都灭绝。由于它们是独立的,它们都灭绝的概率是 \(P(E)^2\)。类似地,对于事件 \(F_4\),有三只变形虫,它们都灭绝的概率是 \(P(E)^3\)。将所有数字代入,方程变为: \[P(E) = \frac{1}{4} \times 1 + \frac{1}{4} \times P(E) + \frac{1}{4} \times P(E)^2 + \frac{1}{4} \times P(E)^3\] 在 \(0 < P(E) < 1\) 的限制下求解此方程,我们将得到 \(P(E) = \sqrt{2} - 1 \approx 0.414\)。
(方程的另外两个根是 \(1\) 和 \(-\sqrt{2} - 1\))。
补充说明: 这个方程的形成依赖于“分支过程”(branching process)的思想:一个群体的灭绝概率可以通过其第一代成员子群体灭绝的概率来求解。这里,变形虫第一代可能产生0、1、2或3个“新的个体”,每个新个体的行为独立且与父代相同,因此灭绝概率满足这个自洽方程。
罐子里的糖果问题
你从一个有 10 颗红色糖果、20 颗蓝色糖果和 30 颗绿色糖果的罐子里一颗一颗地取出糖果。当你取出所有红色糖果时,罐子里至少还有 1 颗蓝色糖果和 1 颗绿色糖果的概率是多少?脚注 16提示: 如果罐子里至少还有 1 颗蓝色糖果和 1 颗绿色糖果,那么最后一颗红色糖果必须在所有 60 颗糖果的序列中,比最后一颗蓝色糖果和最后一颗绿色糖果更早被取出。那么,在 60 颗糖果的序列中,蓝色糖果是最后一颗的概率是多少?在此条件下,在 30 颗糖果(10 颗红色,20 颗绿色)的序列中,最后一颗绿色糖果是最后一颗的概率是多少?如果绿色糖果是 60 颗糖果序列中的最后一颗呢? 解答: 初看之下,这个问题似乎是一个组合问题。
然而,条件概率方法可以给出更直观的答案。设 \(T_r\)、\(T_b\) 和 \(T_g\) 分别表示最后一颗红色、蓝色和绿色糖果被取出的顺序。
原书 PDF 第 96 页补充说明: 如果你很难想象“最后一颗红色糖果被取出时还有蓝和绿糖果”的含义,可以换个角度:这意味着最后一颗红色糖果被取出的时间,早于最后一颗蓝色糖果和最后一颗绿色糖果。换句话说,按所有糖果被取出的顺序,最后一颗红色糖果排在所有糖果中的某个位置,而蓝色和绿色的“最后版本”必须排在它的后面。
查看本页原始扫描图

糖果抽取问题
设 \(T_r, T_b, T_g\) 分别为最后一个红色、蓝色和绿色糖果被取出的序号。为了在所有红色糖果被取出时,至少剩下 1 颗蓝色糖果和 1 颗绿色糖果,我们需要满足 \(T_r < T_b\) 且 \(T_r < T_g\)。换句话说,我们想计算概率 \(P(T_r < T_b \cap T_r < T_g)\)。有两个互斥的事件能满足 \(T_r < T_b\) 和 \(T_r < T_g\),即 \(T_r < T_b < T_g\) 和 \(T_r < T_g < T_b\)。因此, \[ P(T_r < T_b \cap T_r < T_g) = P(T_r < T_b < T_g) + P(T_r < T_g < T_b) \] 事件 \(T_r < T_g < T_b\) 意味着最后一个被取出的糖果是绿色的(即 \(T_g = 60\))。
由于 60 颗糖果中的每一颗都有可能成为最后一个被取出的糖果,并且其中有 30 颗是绿色的,所以有 \[ P(T_g = 60) = \frac{30}{60} \] 在 \(T_g = 60\) 的条件下,我们需要计算 \(P(T_r < T_b | T_g = 60)\)。在剩下的 30 颗红色和蓝色糖果中,每一颗都有可能成为最后一个被取出的糖果,并且有 20 颗是蓝色的,所以 \(P(T_r < T_b | T_g = 60) = \frac{20}{30}\)。因此,\(P(T_r < T_g < T_b) = \frac{30}{60} \times \frac{20}{30}\)。类似地,我们有 \(P(T_r < T_b < T_g) = \frac{20}{60} \times \frac{30}{40}\)。
补充说明: 这里的计算逻辑是:先让某种颜色的糖果成为最后一个(概率为“该颜色糖果数/总糖果数”),然后在剩下的糖果中,再让另一种颜色的糖果成为最后一个(概率为“该颜色糖果数/剩余糖果总数”)。因为事件是分步发生的,所以概率相乘。
因此, \[ P(T_r < T_b \cap T_r < T_g) = P(T_r < T_b < T_g) + P(T_r < T_g < T_b) = \frac{30}{60} \times \frac{20}{30} + \frac{20}{60} \times \frac{30}{40} = \frac{7}{12} \]
抛硬币游戏
两位玩家 A 和 B 轮流抛掷一枚公平的硬币(A 先抛,然后 B 抛,然后 A,然后 B...)。记录下正面(H)和反面(T)的序列。如果出现一个正面后紧接着一个反面(HT 子序列),游戏结束,并且抛出反面的那个人获胜。A 赢得游戏的概率是多少?脚注 17提示:根据 A 的第一次抛掷结果进行条件化并使用对称性。 解: 设 \(P(A)\) 为 A 获胜的概率,则 B 获胜的概率为 \(P(B) = 1 - P(A)\)。让我们根据 A 的第一次抛掷结果来对 \(P(A)\) 进行条件概率分析。A 的第一次抛掷有 1/2 的概率是 H(正面),有 1/2 的概率是 T(反面)。
\[ P(A) = \frac{1}{2} P(A|H) + \frac{1}{2} P(A|T) \] 如果 A 的第一次抛掷是 T,那么 B 实际上成为了第一个可能抛出 H 的人(因为需要 H 才能形成 HT 子序列)。所以我们有 \(P(A|T) = P(B) = 1 - P(A)\)。如果 A 的第一次抛掷是 H,让我们进一步根据 B 的第一次抛掷来条件化。B 有 1/2 的概率得到 T,在这种情况下 A 输。对于 B 得到 H 的 1/2 的概率,B 实际上成为了第一个抛出 H 的人。在这种情况下,A 获胜的概率变为 \( (1- P(A|H)) \)。所以 \( P(A|H) = 1/2 \times 0 + 1/2 (1 - P(A|H)) \Rightarrow P(A|H) = 1/3 \)。
结合所有可用信息,我们有 \[ P(A) = 1/2 \times 1/3 + 1/2 (1 - P(A)) \Rightarrow P(A) = 4/9. \]
补充说明: 这里利用了对称性。当 A 先抛出 H 而 B 也抛出 H 后,局面重置,但此时 B 变成了“先手”的角色,所以 A 获胜的概率等于 B 在原始游戏中获胜的概率,即 \(1 - P(A|H)\)。
合理性检查:我们可以看到 \( P(A) < 1/2 \),这是合理的,因为 A 不可能在他的第一次抛掷中就获胜,而 B 在她的第一次抛掷中却有 1/4 的概率获胜。
原书 PDF 第 97 页查看本页原始扫描图

俄罗斯轮盘赌系列
让我们玩一个传统版本的俄罗斯轮盘赌。一颗子弹被放入一个有 6 个弹膛的左轮手枪中。枪管被随机旋转,使得每个弹膛被置于击锤下的可能性相等。两名玩家轮流扣动扳机——不幸的是,枪口指向自己的头部——并且不再旋转枪管,直到枪响,被杀死的人输掉游戏。如果你,作为其中一名玩家,可以选择先手或后手,你会如何选择?你输掉的概率是多少?解: 许多人错误地认为先手玩家输掉的概率更高。毕竟,在第二名玩家开始之前,第一名玩家在第一轮就有 1/6 的机会被杀死。不幸的是,这是少数直觉出错的情况之一。一旦枪管被旋转,子弹的位置就固定了。如果你先手,你输掉当且仅当子弹在 1、3 或 5 号弹膛。所以你输掉的概率与第二名玩家相同,都是 1/2。从这个意义上说,选择先手还是后手并不重要。现在,让我们稍微改变一下规则。我们将在每次扣动扳机后重新旋转枪管。你会选择成为第一名玩家还是第二名玩家?你输掉的概率是多少?解: 区别在于现在每一轮都是独立的。
假设第一名玩家输掉的概率是 \( p \),那么第二名玩家输掉的概率就是 \( 1-p \)。让我们根据第一名玩家的第一次扣动扳机来进行条件概率分析。他在这一轮有 1/6 的概率输掉。否则,他本质上变成了游戏中的第二名玩家,其新的(条件)输掉概率为 \( 1-p \)。这种情况发生的概率是 5/6。这给我们:\( p = 1 \times 1/6 + (1-p) \times 5/6 \Rightarrow p = 6/11 \)。所以你应该选择成为第二名玩家,这样你输掉的概率是 5/11。如果枪膛里不是一颗子弹,而是随机放入两颗子弹。你的对手先手并且他在第一次扣动扳机后存活了下来。现在给你一个选择:是否要重新旋转枪管。你应该旋转枪管吗?
原书 PDF 第 98 页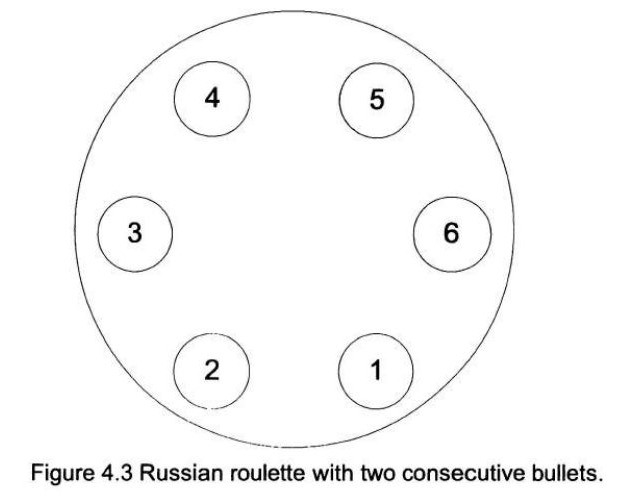
查看本页原始扫描图

俄罗斯轮盘赌(续)
解: 如果你转动转轮,本轮你输掉的概率是 \(2/6\)。如果你不转动转轮,只剩下 5 个弹膛,在你对手存活的条件下,本轮你输掉的概率是 \(2/5\)。所以你应该转动转轮。 如果两颗子弹随机地放在两个连续的位置上?如果你的对手在第一轮存活了,你应该转动转轮吗? 解: 现在我们必须根据两颗子弹的位置是连续的这一事实来计算概率。如图 4.3 所示,我们将空弹膛标记为 1、2、3 和 4;将有子弹的弹膛标记为 5 和 6。由于你的对手在第一轮存活了,他遇到的可能位置是 1、2、3 或 4,概率相等。有 \(1/4\) 的概率,下一个位置是子弹(即位置是 4)。所以如果你不转动,存活的几率是 \(3/4\)。如果你转动转轮,每个位置被选中的概率相等,而你存活的几率只有 \(2/3\)。所以你不应该转动转轮。
A(Aces)问题
一副 52 张牌随机发给 4 位玩家,每位玩家得到 13 张牌。每位玩家都拿到一张 A 的概率是多少?解: 该问题可以使用标准的计数方法来解答。将 52 张牌发给 4 位玩家,每位玩家得到 13 张牌,总共有 \(\frac{52!}{13!13!13!13!}\) 种排列。如果每位玩家需要有一张 A。我们可以先分配 A,有 4!种方法。然后我们将剩下的 48 张牌分给 4 个玩家,每人 12 张,有 $\frac{48!}{12!12!12!12!}$ 种排列。
所以每人有一张 A 的概率是 $$4! \times \frac{48!}{12!12!12!12!} \div \frac{52!}{13!13!13!13!} = \frac{52!}{13!13!13!13!} \times \frac{48!}{12!12!12!12!} \times 4! = \frac{52 \times 39 \times 26 \times 13}{52 \times 51 \times 50 \times 49}$$ 如果使用条件概率方法,逻辑会更清晰。我们从四张 A 中的任意一张开始;它属于某个牌堆的概率是 52/52=1。第二张 A 可以是剩下的 51 张牌中的任意一张,其中 39 张属于与第一张 A 不同的牌堆。所以第二张 A 不在第一张 A 的牌堆中的概率是 39/51。现在剩下 50 张牌,其中 26 张属于另外两个牌堆。
所以,给定前两张 A 已经在不同的牌堆中,第三张 A 属于另外两个牌堆之一的条件概率是 26/50。类似地,给定前三张 A 已经在不同的牌堆中,第四张 A 属于与前三张 A 不同的牌堆的条件概率是 13/49。所以每个牌堆都有一张 A 的概率是 $$1 \times \frac{39}{51} \times \frac{26}{50} \times \frac{13}{49}$$
补充说明: 条件概率法的思路是逐步分配 A。每分配一张 A,就计算它不落入已有 A 的玩家手中的概率。分子是“安全”的牌数(即属于还没有 A 的玩家的牌数),分母是剩余的牌总数。
赌徒破产问题
一位赌徒最初拥有 i 美元。在接下来的每一局游戏中,赌徒以概率 p 赢得 1 美元,其中 $0 < p < 1$,或者以概率 $q = 1-p$ 输掉 1 美元。如果他积累到 N 美元或输光所有钱,他就会停止。他最终拥有 N 美元的概率是多少?解答: 这是一个经典的教科书概率问题,称为赌徒破产问题。有趣的是,它仍然广泛用于量化面试中。从任何初始状态 i(赌徒拥有的美元),$0 \le i \le N$,设 $P_i$ 为赌徒的财富最终达到 N 而不是 0 的概率。下一状态是 i+1(以概率 p)或 i-1(以概率 q)。所以我们有 $$P_i = pP_{i+1} + qP_{i-1} \Rightarrow P_{i+1} - P_i = \frac{q}{p}(P_i - P_{i-1})$$ 我们也有边界概率 $P_0 = 0$ 和 $P_N = 1$。
所以从 $P_2$ 开始,我们可以依次将 $P_i$ 评估为 $P_1$ 的表达式: $$P_{i+1} - P_i = \frac{q}{p}(P_i - P_{i-1}) = \left(\frac{q}{p}\right)^2 (P_{i-1} - P_{i-2}) = \dots = \left(\frac{q}{p}\right)^i (P_1 - P_0)$$
原书 PDF 第 100 页查看本页原始扫描图

\[ P_1 = pP_2 + qP_0 \Rightarrow P_2 = \frac{1}{p}P_1 = \left[1 + \frac{q}{p}\right] P_1 \] \[ P_3 = \left[1 + \frac{q}{p} + \left(\frac{q}{p}\right)^2\right] P_1 \] \[ \dots \] \[ P_i = \left[1 + \frac{q}{p} + \dots + \left(\frac{q}{p}\right)^{i-1}\right] P_1 \] 将这个表达式扩展到 $P_N$,我们有 \[ P_N = 1 = \left[1 + \frac{q}{p} + \dots + \left(\frac{q}{p}\right)^{N-1}\right] P_1 \] \[ \Rightarrow P_1 = \begin{cases} \frac{1 - q/p}{1 - (q/p)^N} P_1, & \text{if } q/p \neq 1 \\ NP_1, & \text{if } q/p = 1 \end{cases} \] \[ \Rightarrow P_i = \begin{cases} \frac{1 - (q/p)^i}{1 - (q/p)^N} P_1, & \text{if } p \neq 1/2 \\ i/N, & \text{if } p = 1/2 \end{cases} \]
补充说明: 赌徒破产问题的解有两种形式,取决于 \(p\) 是否等于 \(1/2\)(即 \(q/p\) 是否等于 1)。当 \(p = 1/2\) 时,输赢机会均等,最终获胜的概率与初始资金占总目标资金的比例 \(i/N\) 成正比。当 \(p \neq 1/2\) 时,概率是一个几何级数的比值。
篮球得分问题
(此部分内容不完整,原文结束于此) 一名篮球运动员正在进行 100 次罚球。如果球穿过篮筐,她得 1 分;如果她投丢,则得 0 分。她的第一次罚球投中了,第二次罚球投丢了。对于之后的每一次罚球,她得分的概率等于到目前为止她投中的罚球次数所占的比例。例如,如果她在第 40 次罚球后得到了 23 分,那么她在第 41 次罚球得分的概率就是 23/40。在 100 次罚球之后(包括第一次和第二次),请问她恰好投中 50 个篮的概率是多少?
脚注 18提示: 同样,不要被数字 100 吓到。从最小的 $n$ 开始,解决问题;尝试增加 $n$ 来找规律;并使用归纳法证明该规律。 解: 令 $(n,k)$,其中 $1 \le k \le n$,表示该运动员在 $n$ 次罚球后投中了 $k$ 个篮的事件,并记 $P_{n,k} = P((n,k))$。如果我们从 $n=3$ 开始使用归纳法,解答会惊人地简单。第三次罚球的得分概率是 1/2。因此我们有 $P_{3,1}=1/2$ 和 $P_{3,2}=1/2$。对于 $n=4$ 的情况,我们应用全概率定律:
原书 PDF 第 101 页查看本页原始扫描图

\[ \begin{cases} P_{4,1} = P((4,1)|(3,1)) \times P_{3,1} + P((4,1)|(3,2)) \times P_{3,2} = \frac{2}{3} \times \frac{1}{2} + 0 \times \frac{1}{2} = \frac{1}{3} \\ P_{4,2} = P((4,2)|(3,1)) \times P_{3,1} + P((4,2)|(3,2)) \times P_{3,2} = \frac{1}{3} \times \frac{1}{2} + \frac{1}{3} \times \frac{1}{2} = \frac{1}{3} \\ P_{4,3} = P((4,3)|(3,1)) \times P_{3,1} + P((4,3)|(3,2)) \times P_{3,2} = 0 \times \frac{1}{2} + \frac{2}{3} \times \frac{1}{2} = \frac{1}{3} \end{cases} \] 结果表明,对于所有 $k=1,2,\dots,n-1$,都有 $P_{n,k} = \frac{1}{n-1}$,这提示我们可以使用全概率定律来进行归纳步骤。
归纳步骤: 假设对于所有 $k=1,2,\dots,n-1$,都有 $P_{n,k} = \frac{1}{n-1}$。我们需要证明对于所有 $k=1,2,\dots,n$,都有 $P_{n+1,k} = \frac{1}{(n+1)-1} = \frac{1}{n}$。为了证明这一点,只需应用全概率定律: $P_{n+1,k} = P(\text{投丢}|(n,k))P_{n,k} + P(\text{投中}|(n,k-1))P_{n,k-1}$ $= \left(1-\frac{k}{n}\right)\frac{1}{n-1} + \frac{k-1}{n}\frac{1}{n-1} = \frac{1}{n}$ 该方程对于 $P_{n+1,1}$ 和 $P_{n+1,n}$ 也同样适用,尽管在这两种情况下,分别有 $\frac{k-1}{n}=0$ 和 $(1-\frac{k}{n})=0$ 成立。
因此我们得到,对于所有 $k=1,2,\dots,n-1$ 以及所有 $n \ge 2$,都有 $P_{n,k} = \frac{1}{n-1}$。所以,$P_{100,50} = 1/99$。
补充说明: 这个结论初看可能有些反直觉,因为直觉上,投中50个篮的概率似乎应该很低。但仔细思考,由于每次投篮的命中概率都动态地等于当前命中率(即已中篮数除以总投篮数),这实际上产生了一个非常均匀的分布:经过 $n$ 次投篮后,最终投中 $k$ 次($k$ 从 1 到 $n-1$)的概率是完全相等的,都等于 $1/(n-1)$。你可以把它想象成:除了第一次必定命中、第二次必定投丢之外,你在剩余 $n-2$ 次投篮中,最终的总命中数会均匀地分布在 1 到 $n-1$ 之间的每一个整数上。
路上汽车
如果在任何一个 20 分钟的时间间隔内,观察到至少一辆汽车的概率是 609/625,那么在任何 5 分钟的时间间隔内观察到至少一辆汽车的概率是多少?假设在整个 20 分钟内,在任何时刻看到汽车的概率是均匀的(恒定的)。 解: 我们可以将一个 20 分钟的时间间隔分解成 4 个不重叠的 5 分钟时间间隔的序列。由于观察到汽车的默认概率是恒定的,因此在任何 5 分钟时间间隔内观察到汽车的概率也是恒定的。我们用 $p$ 来表示这个概率,那么在任何一个 5 分钟时间间隔内我们没有观察到汽车的概率就是 $1-p$。
原书 PDF 第 102 页
查看本页原始扫描图

我们在所有四个独立的 5 分钟时间间隔内都没有观察到任何汽车的概率是 \((1-p)^4 = 1 - 609/625 = 16/625\),由此得出 \(p = 3/5\)。
补充说明: 这里的核心思想是将一个较长的时间段划分为若干个独立、不重叠的较短时间段。因为“在任何 5 分钟内至少看到一辆车”和它的反面“在某 5 分钟内一辆车都没看到”是互补事件。由于每个 5 分钟时间段是独立的,那么连续 4 个 5 分钟时间段都没看到车的概率,就是单个时间段没看到车概率的 4 次方。而“20 分钟里至少看到一辆车”的反面正是“连续 4 个 5 分钟时间段都没看到车”,所以我们就可以建立方程来求解 $p$。
4.4 离散型和连续型分布
在本节中,我们将回顾量化建模中广泛使用的各种随机变量的分布函数。虽然不一定需要记住这些分布的所有性质,但能够直观地理解这些分布并能够快速推导出重要性质,是在实践中非常有价值的技能。照例,我们先从理论开始: 随机变量的常用函数 表 4.1 总结了离散型和连续型随机变量的基本性质是如何定义或计算的。这些是您应该牢记的基础知识。
| 随机变量 (X) | 离散型 | 连续型19 | 5a-55LqO6L-e57ut5Z6L6ZqP5py65Y-Y6YeP77yM5a-55LqO5omA5pyJIFwoeCBcaW4gKC1caW5mdHksIFxpbmZ0eSlcKe-8jOaciSBcKFAoWCA9IHgpID0gMFwp77yM5Zug5q2kIFwoUFx7WCBcbGUgeFx9ID0gUFx7WCA8IHhcfVwp44CC |
|---|---|---|---|
| 累积分布函数 (cdf) | \(F(a) = P\{X \le a\}\) | \(F(a) = \int_{-\infty}^{a} f(x)dx\) | |
| 概率质量函数 (pmf) 概率密度函数 (pdf) | pmf: \(p(x) = P\{X = x\}\) | pdf: \(f(x) = \frac{d}{dx}F(x)\) | |
| 期望值 \(E[X]\) | \(\sum_{x:p(x)>0} xp(x)\) | \(\int_{-\infty}^{\infty} xf(x)dx\) | |
| \(g(X)\) 的期望值 \(E[g(X)]\) | \(\sum_{x:p(x)>0} g(x)p(x)\) | \(\int_{-\infty}^{\infty} g(x)f(x)dx\) | |
| 方差 \(\text{var}(X)\) | \(E[(X - E[X])^2] = E[X^2] - (E[X])^2\) | \(E[(X - E[X])^2] = E[X^2] - (E[X])^2\) | |
| 标准差 \(\text{std}(X)\) | \(\sqrt{var(X)}\) | \(\sqrt{var(X)}\) |
表 4.1 离散型和连续型随机变量的基本性质 离散型随机变量 表 4.2 包含了一些最广泛使用的离散分布。离散均匀随机变量 表示当集合 \(\{a, a+1, \dots, b\}\) 中的所有值出现概率相等时,在数字 \(a\) 和 \(b\) 之间产生一个值的事件。二项随机变量 表示在一系列 \(n\) 次试验中成功的次数,其中每次试验是
原书 PDF 第 103 页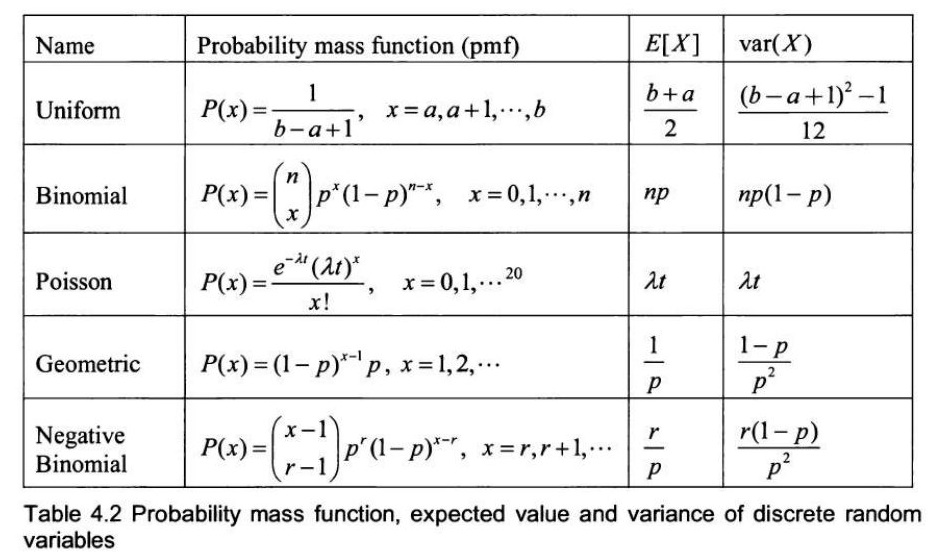
查看本页原始扫描图
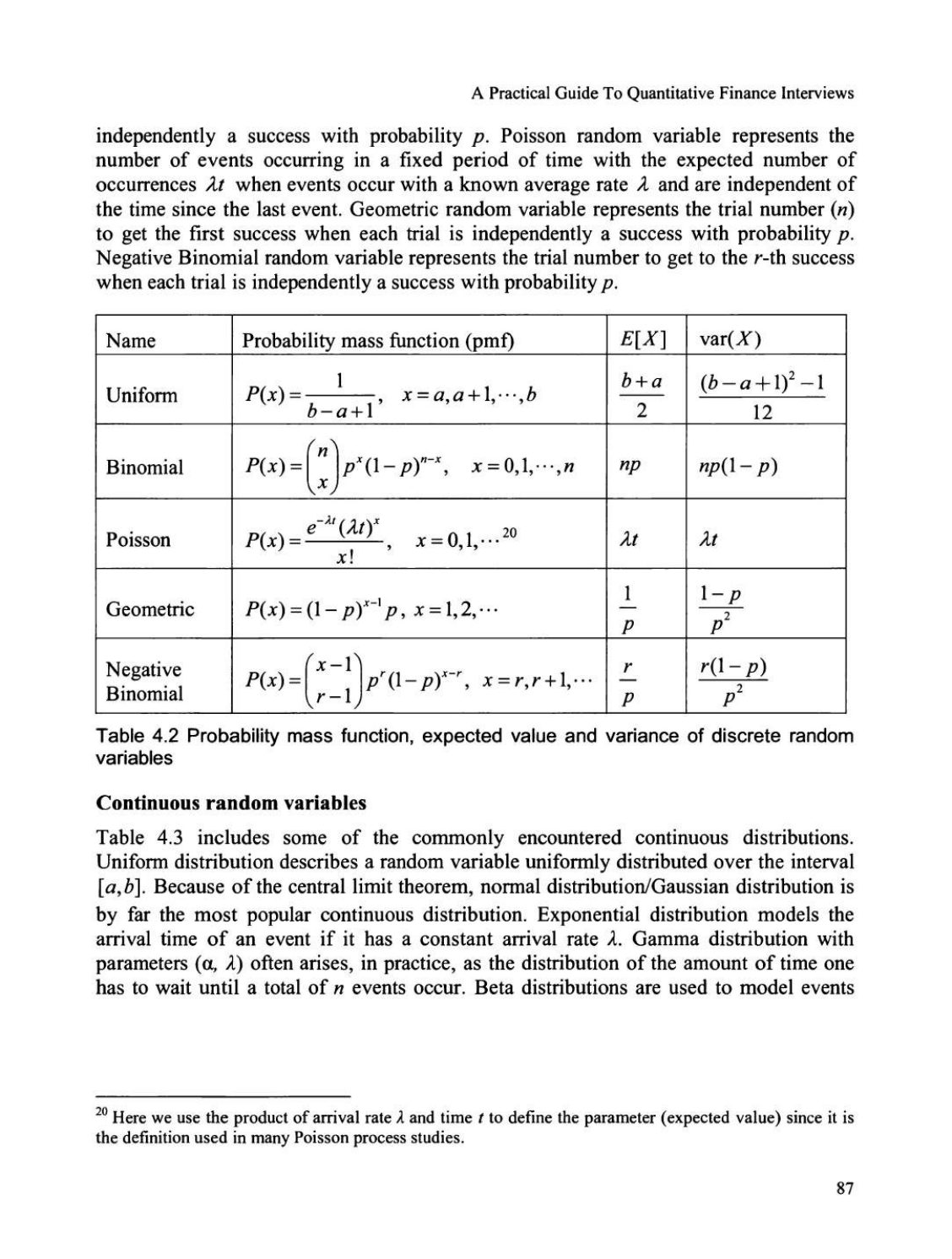
独立地以概率 \(p\) 获得成功。泊松随机变量 表示在固定时间段内发生的事件数量,其期望发生次数为 \(\lambda t\),当事件以已知的平均速率 \(\lambda\) 发生,并且与上一个事件发生以来的时间无关时。几何随机变量 表示在每次试验独立地以概率 \(p\) 获得第一次成功所需的试验次数 \((n)\)。负二项随机变量 表示在每次试验独立地以概率 \(p\) 获得第 \(r\) 次成功所需的试验次数。 | 名称 | 概率质量函数 (pmf)
原书 PDF 第 104 页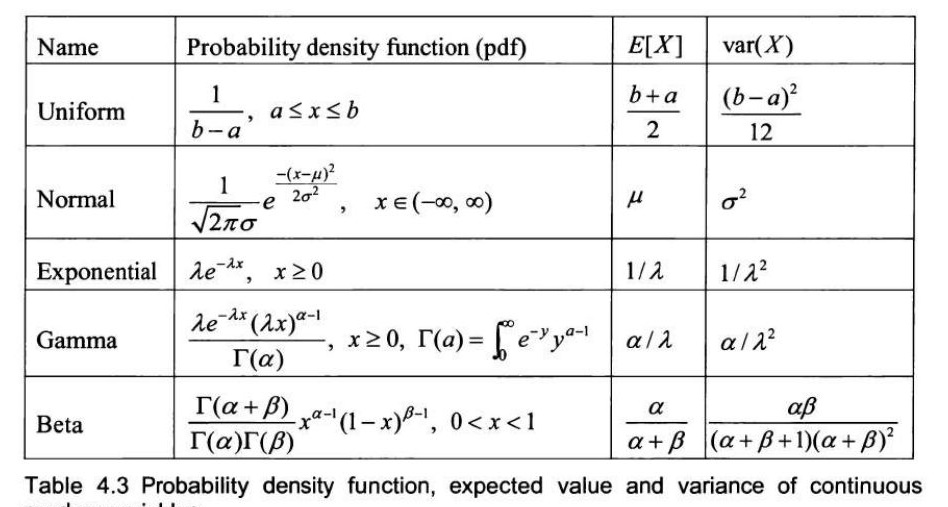
查看本页原始扫描图

被约束在一个定义的区间内。通过调整形状参数 \(\alpha\) 和 \(\beta\),它可以模拟不同形状的概率密度函数。\(^{21}\)
| 名称 | 概率密度函数 (pdf) | E[X] | var(X) |
|---|---|---|---|
| 均匀分布 | \( \frac{1}{b-a}, \quad a \le x \le b \) | \( \frac{b+a}{2} \) | \( \frac{(b-a)^2}{12} \) |
| 正态分布 | \( \frac{1}{\sqrt{2\pi}\sigma} e^{-\frac{(x-\mu)^2}{2\sigma^2}}, \quad x \in (-\infty, \infty) \) | \( \mu \) | \( \sigma^2 \) |
| 指数分布 | \( \lambda e^{-\lambda x}, \quad x \ge 0 \) | \( 1/\lambda \) | \( 1/\lambda^2 \) |
| 伽马分布 | \( \frac{\lambda e^{-\lambda x} (\lambda x)^{\alpha-1}}{\Gamma(\alpha)}, \quad x \ge 0, \Gamma(a) = \int_0^\infty e^{-y} y^{a-1} dy \) | \( \alpha/\lambda \) | \( \alpha/\lambda^2 \) |
| 贝塔分布 | \( \frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\beta)} x^{\alpha-1} (1-x)^{\beta-1}, \quad 0 < x < 1 \) | \( \frac{\alpha}{\alpha+\beta} \) | \( \frac{\alpha\beta}{(\alpha+\beta)^2(\alpha+\beta+1)} \) |
碰面概率
两位银行家各自在一个随机时间到达车站,时间范围是上午 5:00 到上午 6:00 之间(两人的到达时间均服从均匀分布)。他们恰好停留五分钟,然后离开。请问他们在某一天相遇的概率是多少?解: 假设银行家 A 在早上 5:00 之后 \(X\) 分钟到达,银行家 B 在早上 5:00 之后 \(Y\) 分钟到达。\(X\) 和 \(Y\) 是相互独立的,并在 0 到 60 之间服从均匀分布。由于两人都只停留五分钟,如图 4.4 所示,A 和 B 会相遇当且仅当 \(|X - Y| \le 5\)。
因此,A 和 B 会相遇的概率就是阴影部分的面积除以正方形的面积(剩余的区域可以组合成一个边长为 55 的正方形): \[ \frac{60 \times 60 - 2 \times (\frac{1}{2} \times 55 \times 55)}{60 \times 60} = \frac{(60+55) \times (60-55)}{60 \times 60} = \frac{23}{144}. \]
补充说明: 这个问题是“几何概型”的一个经典例子。我们用一个二维图形来表示所有可能的到达时间组合,横纵坐标分别代表 \(X\) 和 \(Y\),取值范围 0 到 60,形成一个大正方形。正方形内每一个点都代表一种可能的到达时间组合。条件 \(|X - Y| \le 5\) 代表两条斜线之间的带状区域。因此,所求概率就是满足条件的区域面积与总区域面积的比值。
\(^{21}\) 例如,贝塔分布在风险管理中被广泛用于对违约损失率进行建模。如果你熟悉贝叶斯统计,你也会发现它是常用的共轭先验分布函数。
原书 PDF 第 105 页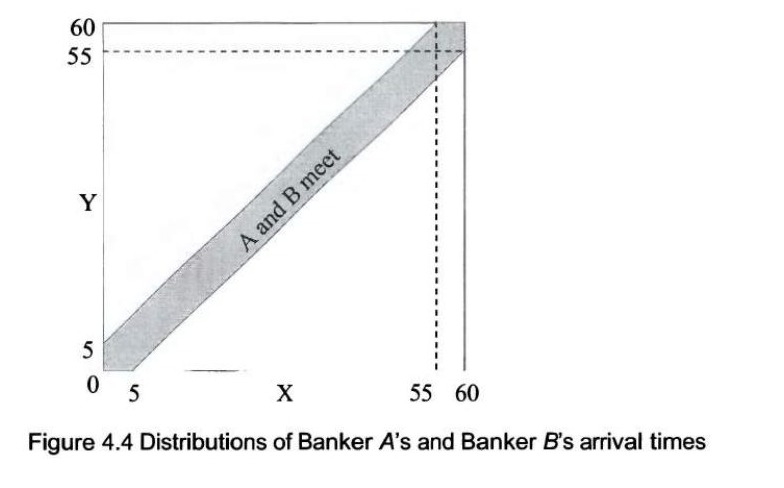
查看本页原始扫描图
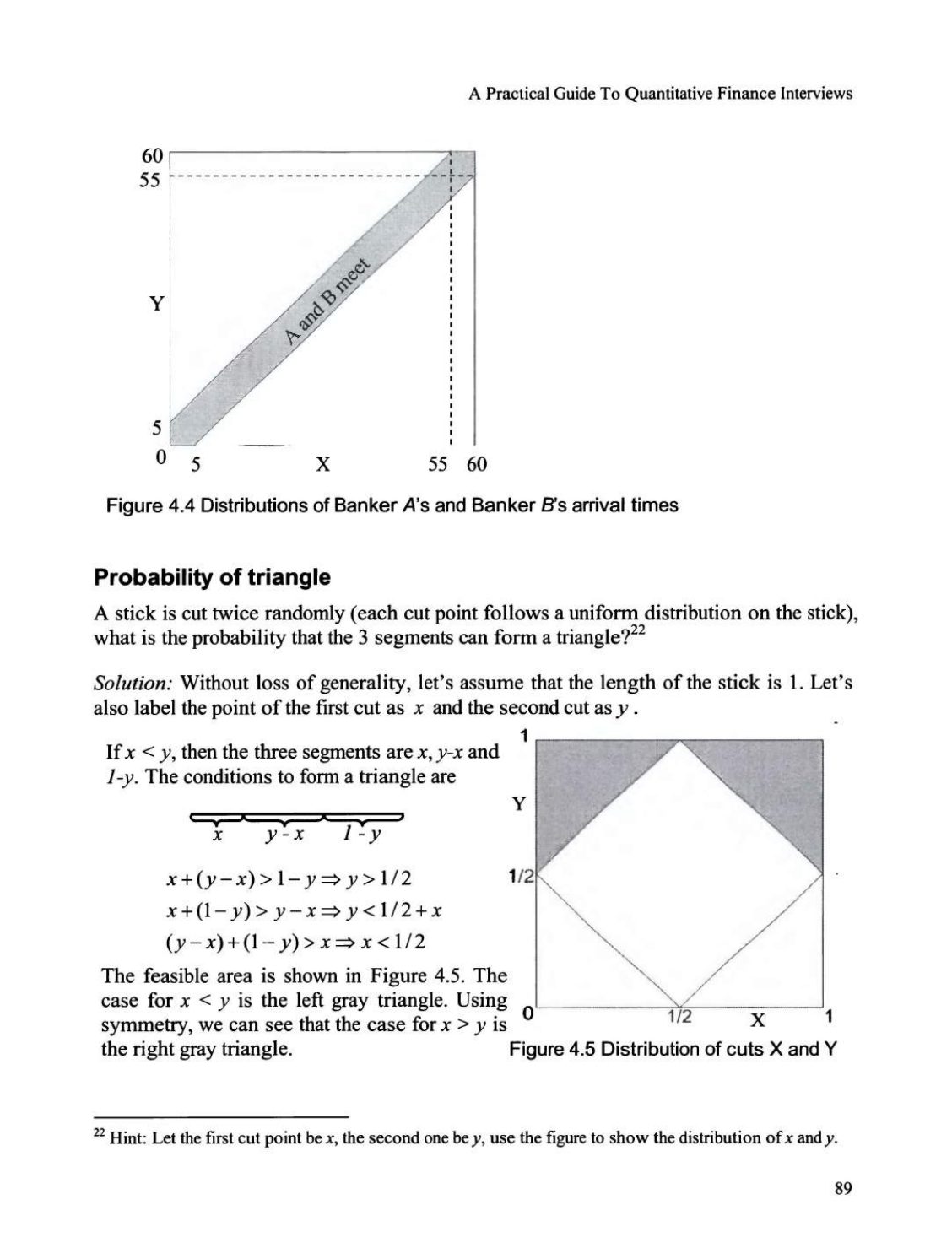
图 4.4 银行家 A 和银行家 B 到达时间的分布
形成三角形的概率
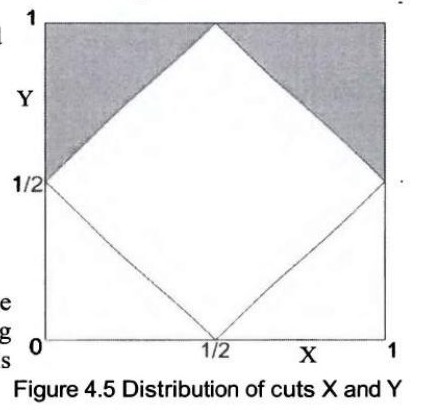
一根棍子被随机切割两次(每个切割点在棍子上服从均匀分布),那么这三段能构成一个三角形的概率是多少?脚注 22提示:设第一次切割点为 \(x\),第二次切割点为 \(y\),利用图形展示 \(x\) 和 \(y\) 的分布。 解答: 不失一般性,我们假设棍子的长度为1。同时,我们将第一次切割的点标记为 \(x\),第二次切割的点标记为 \(y\)。如果 \(x < y\),那么三段长度分别为 \(x\)、\(y-x\) 和 \(1-y\)。
能构成三角形的条件是: \[ \begin{array}{l} x + (y-x) > 1-y \Rightarrow y > 1/2 \\ x + (1-y) > y-x \Rightarrow y < 1/2 + x \\ (y-x) + (1-y) > x \Rightarrow x < 1/2 \end{array} \] 可行区域如图4.5所示。\(x < y\) 的情况对应左侧的灰色三角形。利用对称性,我们可以看到 \(x > y\) 的情况对应右侧的灰色三角形。
原书 PDF 第 106 页查看本页原始扫描图

总的阴影区域代表三段能构成三角形的区域,它占整个正方形的1/4。所以概率是1/4。
泊松过程的性质
你在公交车站等车。公交车按照泊松过程到达车站,平均到达时间为10分钟(\(\lambda = 0.1/\text{分钟}\))。如果公交车已经运行了很长时间,并且你在一个随机时间到达公交车站,那么你的期望等待时间是多少?平均而言,上一班公交车是几分钟前离开的?解答: 考虑到跳跃扩散过程在衍生品定价中的重要性,以及泊松过程在研究跳跃过程中的作用,我们更详细地阐述指数随机变量和泊松过程。指数分布被广泛用于模拟以恒定平均速率(到达率)\(\lambda\) 发生的独立事件之间的时间间隔: \[ f(t) = \begin{cases} \lambda e^{-\lambda t} & (t \ge 0) \\ 0 & (t < 0) \end{cases} \] 期望到达时间为 \(1/\lambda\),方差为 \(1/\lambda^2\)。
通过积分,我们可以计算出指数分布的累积分布函数为 \(F(t) = P(\tau \le t) = 1 - e^{-\lambda t}\),并且 \(P(\tau > t) = e^{-\lambda t}\),其中 \(\tau\) 是到达时间的随机变量。指数分布的一个独特性质是无记忆性:\(P\{\tau > s+t | \tau > s\} = P(\tau > t)\)。脚注 23\(P\{\tau > s+t | \tau > s\} = e^{-\lambda(s+t)} / e^{-\lambda s} = e^{-\lambda t} = P(\tau > t)\) 这意味着如果我们已经等待了 \(s\) 个单位时间,那么额外的等待时间与我们从时间0开始等待的时间具有相同的分布。
当一系列事件的到达各自独立地服从到达率为 \(\lambda\) 的指数分布时,在时间0到 \(t\) 之间的到达次数可以建模为泊松过程:\(P(N(t) = x) = \frac{e^{-\lambda t} (\lambda t)^x}{x!}\),\(x = 0, 1, \dots\)。脚注 24更严格地说,\(N(t)\) 被定义为一个右连续函数。 期望到达次数是 \(\lambda t\),方差也是 \(\lambda t\)。由于指数分布的无记忆性,时间 \(s\) 到 \(t\) 之间的到达次数也是一个泊松过程:\(P(N(t-s) = x) = \frac{e^{-\lambda(t-s)} (\lambda(t-s))^x}{x!}\)。
利用指数分布的无记忆性,我们知道期望等待时间是 \(1/\lambda = 10\) 分钟。如果你回顾过去,无记忆性仍然适用。所以平均而言,上一班公交车也是在10分钟前到达的。
原书 PDF 第 107 页查看本页原始扫描图

这是另一个例子,可能会误导你的直觉。你可能在想,如果最后一班公交车平均在10分钟前到达,而下一班公交车平均将在10分钟后到达,那么平均到达时间间隔不应该是20分钟而不是10分钟吗?造成这种明显差异的解释是,当你随机到达时,你更有可能出现在两次公交车到达之间的时间间隔较长的时候,而不是较短的时候。例如,如果两次公交车到达之间的一个间隔是30分钟,而另一个间隔是5分钟,那么你更有可能出现在那个30分钟的间隔内,而不是5分钟的间隔内。事实上,如果你随机到达,那么对于一个一般的分布,预期的剩余寿命(下一班公交车到达的时间)是: \[ \frac{E[X^2]}{2E[X]} \]
正态分布的矩
如果X服从标准正态分布(\(X \sim N(0, 1)\)),那么当 \(n = 1, 2, 3\) 和4时,\(E[X^n]\) 是多少?解答: 标准正态分布的前四个矩分别是均值、方差、偏度和峰度。所以你可能已经记住了答案分别是0、1、0(无偏度)和3。标准正态分布的概率密度函数为 \(f(x) = \frac{1}{\sqrt{2\pi}}e^{-x^2/2}\)。利用简单的对称性,当n为奇数时,我们有 \(E[X^n] = \int_{-\infty}^{\infty} x^n \frac{1}{\sqrt{2\pi}}e^{-x^2/2}dx = 0\)。对于n=2,通常使用分部积分法。要解决任意整数n的 \(E[X^n]\) 问题,使用矩生成函数的方法可能是一个更好的选择。
矩生成函数定义为: \[ M(t) = E[e^{tX}] = \begin{cases} \sum_{x} e^{tx} p(x), & \text{如果 } x \text{ 是离散的} \\ \int_{-\infty}^{\infty} e^{tx} f(x)dx, & \text{如果 } x \text{ 是连续的} \end{cases} \] 顺序地对M(t)求导,我们得到M(t)的一个常用性质: \[ M'(t) = \frac{d}{dt} E[e^{tX}] = E[Xe^{tX}] \Rightarrow M'(0) = E[X], \] \[ M''(t) = \frac{d}{dt} E[Xe^{tX}] = E[X^2e^{tX}] \Rightarrow M''(0) = E[X^2], \]
原书 PDF 第 108 页查看本页原始扫描图

并且一般来说,\(M^{(n)}(0) = E[X^n]\),\(\forall n \geq 1\)。我们可以利用这个性质来求解 \(X \sim N(0, 1)\) 时的 \(E[X^n]\)。对于标准正态分布,\(M(t) = E[e^{tX}] = \int_{-\infty}^{\infty} e^{tx} \frac{1}{\sqrt{2\pi}} e^{-x^2/2} dx = e^{t^2/2} \int_{-\infty}^{\infty} \frac{1}{\sqrt{2\pi}} e^{-(x-t)^2/2} dx\)。(\(\frac{1}{\sqrt{2\pi}}e^{-(x-t)^2/2}\) 是正态分布 \(X \sim N(t, 1)\) 的概率密度函数,所以 \(\int_{-\infty}^{\infty} f(x) dx = 1\))。
求导后,我们有 \(M'(t) = te^{t^2/2} \Rightarrow M'(0) = 0\),\(M''(t) = e^{t^2/2} + t^2e^{t^2/2} \Rightarrow M''(0) = e^0 = 1\), \(M^{(3)}(t) = te^{t^2/2} + 2te^{t^2/2} + t^3e^{t^2/2} = 3te^{t^2/2} + t^3e^{t^2/2} \Rightarrow M^{(3)}(0) = 0\), 并且 \(M^{(4)}(t) = 3e^{t^2/2} + 3t^2e^{t^2/2} + 3t^2e^{t^2/2} + t^4e^{t^2/2} \Rightarrow M^{(4)}(0) = 3e^0 = 3\)。
4.5 期望值、方差与协方差
期望值、方差和协方差在评估任何投资的收益和风险时都是不可或缺的。自然地,它们也是面试中常见的测试主题。基础知识包括以下内容: 如果对于所有 \(i=1, \dots, n\),\(E[X_i]\) 都是有限的,那么 \(E[X_1 + \dots + X_n] = E[X_1] + \dots + E[X_n]\)。无论这些 \(x_i\) 之间是否相互独立,这个关系都成立。如果X和Y是独立的,那么 \(E[g(X)h(Y)] = E[g(X)]E[h(Y)]\)。协方差:\(Cov(X,Y) = E[(X - E[X])(Y - E[Y])] = E[XY] - E[X]E[Y]\)。相关系数:\(\rho(X,Y) = \frac{Cov(X,Y)}{\sqrt{Var(X)Var(Y)}}\) 如果X和Y是独立的,那么 \(Cov(X,Y) = 0\) 且 \(\rho(X,Y) = 0\)。
脚注 26反之则不成立。\(\rho(X,Y) = 0\) 仅意味着X和Y不相关;它们很可能存在依赖关系。 方差和协方差的一般规则:
| \(Cov(\sum_{i=1}^{n} a_i X_i, \sum_{j=1}^{m} b_j Y_j) = \sum_{i=1}^{n} \sum_{j=1}^{m} a_i b_j Cov(X_i, Y_j)\) |
| \(Var(\sum_{i=1}^{n} X_i) = \sum_{i=1}^{n} Var(X_i) + 2 \sum_{i |
条件期望与方差
对于离散分布: \[ E[g(X)|Y = y] = \sum_{x} g(x) p_{X|Y}(x|y) = \sum_{x} g(x) p(X=x|Y=y) \] 对于连续分布: \[ E[g(X)|Y = y] = \int_{-\infty}^{\infty} g(x) f_{X|Y}(x|y) dx \] 全期望定律(Law of Total Expectation): \[ E[X] = E[E[X|Y]] = \left\{ \begin{array}{ll} \sum_{y} E[X|Y=y]p(Y=y), & \text{当Y为离散变量时} \\ \int_{-\infty}^{\infty} E[X|Y=y]f_Y(y)dy, & \text{当Y为连续变量时} \end{array} \right. \]
连接面条(Noodle Problem)
你的汤碗里有100根面条。你蒙着眼睛,被告知要随机拿起碗里一些面条的两端(每根面条的每一端被选中的概率相同)并将它们连接起来。你一直这样做,直到没有自由的末端为止。这样形成的圈的数量是随机的。计算圈的期望数量。解: 再次提醒,不要被数字100吓倒。如果你不知道如何开始,让我们从最简单的情况开始:当 \(n=1\) 时,你肯定只有一个选择(连接同一根面条的两端),所以形成的圈数一定是1,即 \(E[f(1)]=1\)。那么 \(n=2\) 呢?现在你有4个末端(2根面条×2),你可以连接任意两个。总共有 \(\binom{4}{2} = \frac{4 \times 3}{2} = 6\) 种组合方式。其中,有2种组合会将同一根面条的两端连接在一起,这样就会形成1个圈和剩下1根面条。另外4种选择则只会将不同面条的末端连起来,结果只是形成一根更长的面条(没有形成圈)。
所以圈的期望数量是: \[ E[f(2)] = \frac{2}{6} \times (1 + E[f(1)]) + \frac{4}{6} \times E[f(1)] = \frac{1}{3} + E[f(1)] = \frac{1}{3} + 1 \] 我们现在来看3根面条的情况。总共有 \(\binom{6}{2} = \frac{6 \times 5}{2} = 15\) 种选择。其中,有3种选择会形成1个圈和剩下2根面条;另外12种选择只会形成2根面条(没有圈)。所以: \[ E[f(3)] = \frac{3}{15} \times (1 + E[f(2)]) + \frac{12}{15} \times E[f(2)] = \frac{1}{5} + E[f(2)] = \frac{1}{5} + \frac{1}{3} + 1 \] 看到规律了吗?
对于任意 \(n\) 根面条,我们将有: \[ E[f(n)] = 1 + \frac{1}{3} + \frac{1}{5} + \cdots + \frac{1}{2n-1} \] 这可以通过数学归纳法轻松证明。代入 \(n=100\),即可得到答案。
原书 PDF 第 110 页查看本页原始扫描图

实际上,在分析完2根面条的情况后,你可能已经找到了这个问题的关键。如果你从 \(n\) 根面条开始,在 \(\binom{2n}{2}\) 种可能的连接组合中,我们有: \[ \frac{n}{n(2n-1)} = \frac{1}{2n-1} \] 的概率会形成1个圈和剩下的 \(n-1\) 根面条,以及: \[ \frac{2n-2}{2n-1} \] 的概率会只形成 \(n-1\) 根面条(没有形成圈)。因此,我们可以得到递推关系:\(E[f(n)] = E[f(n-1)] + \frac{1}{2n-1}\)。从这个关系式往回推导,你也能得到最终的解决方案。
最优对冲比率(Optimal Hedge Ratio)
你刚刚买入了一股股票A,并希望通过卖空股票B来对冲其风险。为了最小化对冲后投资组合的方差,你应该卖空多少股股票B?假设股票A的收益率方差为 \(\sigma_A^2\);股票B的收益率方差为 \(\sigma_B^2\);它们的相关系数为 \(\rho\)。解: 假设我们卖空了 \(h\) 股股票B,那么投资组合的收益率方差为: \[ \text{var}(r_A - hr_B) = \sigma_A^2 - 2\rho h \sigma_A \sigma_B + h^2 \sigma_B^2 \] 最优对冲比率应该最小化 \(\text{var}(r_A - hr_B)\)。
对 \(h\) 求一阶偏导数并令其等于零: \[ \frac{\partial \text{var}}{\partial h} = -2\rho \sigma_A \sigma_B + 2h \sigma_B^2 = 0 \Rightarrow h = \rho \frac{\sigma_A}{\sigma_B} \] 为了确认这是最小值,我们还可以检查二阶偏导数: \[ \frac{\partial^2 \text{var}}{\partial h^2} = 2\sigma_B^2 > 0 \] 所以,当 \(h = \rho \frac{\sigma_A}{\sigma_B}\) 时,对冲后的投资组合确实具有最小方差。
补充说明: 这个结果很直观。对冲比率 \(h\) 取决于两个股票的波动率之比(\(\sigma_A / \sigma_B\))和它们的相关性(\(\rho\))。如果两个股票完全正相关(\(\rho=1\)),你需要卖空 \(\sigma_A/\sigma_B\) 股B来对冲1股A;如果它们完全负相关(\(\rho=-1\)),你会卖空负的数量的B,实际上是买入B来对冲。如果它们不相关(\(\rho=0\)),卖空B无法降低风险,最佳头寸是不对冲。
骰子游戏
假设你掷一个骰子。每次掷骰,你都会获得与骰子面值相等的金额。如果一次掷出的结果是4、5或6,你可以再掷一次;一旦你掷出1、2或3,游戏结束。问这个游戏的期望收益是多少? 解: 这是全期望定律(Law of Total Expectation)的一个应用示例。你的收益显然取决于第一次投掷的结果。设 \(E[X]\) 是你的期望收益,\(Y\) 是第一次投掷的结果。你有1/2的概率得到 \(Y \in \{1,2,3\}\),在这种情况下,期望收益就是这轮的点数期望值(即2),所以 \(E[X | Y \in \{1,2,3\}] = 2\);你有
原书 PDF 第 111 页查看本页原始扫描图

1/2的概率得到 \(Y \in \{4, 5, 6\}\),在这种情况下,你将获得这一轮的点数期望值(即5),并且还能够继续掷骰。继续掷骰本质上意味着你重新开始游戏,并获得额外的期望值 \(E[X]\)。因此,我们有 \(E[X | Y \in \{4,5,6\}] = 5 + E[X]\)。应用全期望定律,我们得到: \[ E[X] = E[E[X | Y]] = \frac{1}{2} \times 2 + \frac{1}{2} \times (5 + E[X]) \Rightarrow E[X] = 7 \]
纸牌游戏
在标准的52张牌的牌堆中,需要翻开多少张牌才能看到第一张A?解: 有4张A和48张其他牌。我们将这48张非A的牌标记为牌1, 2, ..., 48。令: \[ X_i = \begin{cases} 1, & \text{如果牌}i\text{在所有4张A之前被翻开} \\ 0, & \text{否则} \end{cases} \] 为了看到第一张A而需要翻开的总牌数为 \(X = 1 + \sum_{i=1}^{48} X_i\),所以我们有 \(E[X] = 1 + \sum_{i=1}^{48} E[X_i]\)。如以下序列所示,每张牌 \(i\) 都同样有可能出现在由4张A分隔开的五个区域之一: 1 A 2 A 3 A 4 A 5 因此,牌 \(i\) 在所有4张A之前出现的概率是1/5,我们有 \(E[X_i] = 1/5\)。
因此,\(E[X] = 1 + \sum_{i=1}^{48} E[X_i] = 1 + 48/5 = 10.6\)。
补充说明: 这个结果很容易记住。把A看作特殊牌,其他牌看作普通牌。在你随机洗牌之后,第一张特殊牌(这里是第一张A)出现在所有特殊牌之前的概率是1/(n+1),其中n是特殊牌的数量。在这里,有4张A(n=4)和m=48张普通牌,所以期望位置是1 + m/(n+1)。
这只是普通牌 \(m\) 张和特殊牌 \(n\) 张随机排序的一个特例。第一张特殊牌的期望位置是 \(1 + \sum_{i=1}^{m} E[X_i] = 1 + \frac{m}{n+1}\)。
随机变量之和
假设 \(X_1, X_2, \dots, X_n\) 是独立同分布(IID,即Independent and Identically Distributed)的随机变量,它们在0和1之间服从均匀分布。求 \(S_n = X_1 + X_2 + \dots + X_n \le 1\) 的概率? 脚注 27你也会看到这个问题可以使用第5章中的Wald定理来解决。 脚注 28提示:从 \(n=1, 2, 3\) 的最简单情况开始。尝试找到一个通用公式,并使用归纳法证明它。
原书 PDF 第 112 页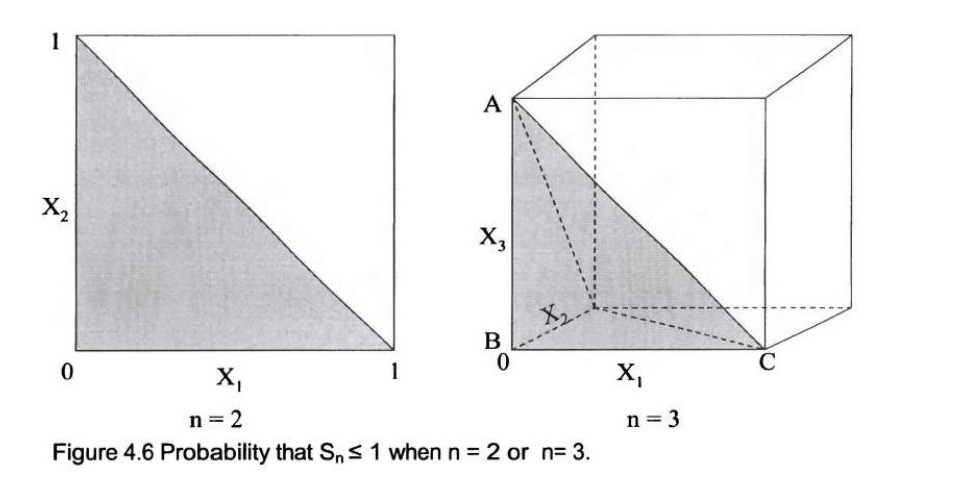
查看本页原始扫描图
解:
这个问题相当困难。从最简单的情况入手并尝试找到规律的通用原则将再次帮助你解决问题;尽管它可能无法直接给你最终答案。当 \(n=1\) 时,\(P(S_1 \le 1) = 1\)。如图4.6所示,当 \(n=2\) 时,\(X_1 + X_2 \le 1\) 的概率就是边长为1的正方形内,满足 \(X_1 + X_2 \le 1\) 这一条件的区域(即三角形)。所以 \(P(S_2 \le 1) = 1/2\)。当 \(n=3\) 时,概率变成边长为1的立方体内,满足 \(X_1 + X_2 + X_3 \le 1\) 这一条件的四面体ABCD的体积。四面体ABCD的体积是 \(1/6\)。
脚注 29你可以通过积分推导出来:\[ \int_0^1 A(z)dz = \int_0^1 \frac{1}{2}z^2 dz = 1/6 \],其中 \(A(z)\) 是在高度 \(z\) 处的截面面积,其形状是一个等腰直角三角形,面积为 \(z^2/2\)。 所以 \(P(S_3 \le 1) = 1/6\)。现在我们可以猜测答案是 \(1/n!\)。为了证明它,我们再次采用归纳法。假设 \(P(S_n \le 1) = 1/n!\)。
我们需要证明 \(P(S_{n+1} \le 1) = 1/(n+1)!\)。
这里我们可以使用条件概率。对 \(X_{n+1}\) 的值进行条件化,我们得到: \[ P(S_{n+1} \le 1) = \int_0^1 f(X_{n+1}) P(S_n \le 1 - X_{n+1}) dX_{n+1} \] 其中 \(f(X_{n+1})\) 是 \(X_{n+1}\) 的概率密度函数,因为它是均匀分布,所以 \(f(X_{n+1}) = 1\)。但是我们如何计算 \(P(S_n \le 1 - X_{n+1})\) 呢?\(n=2\) 和 \(n=3\) 的情况已经给了我们一些线索。
对于 \(S_n \le 1 - X_{n+1}\),而不是 \(S_n \le 1\),我们实际上需要将 \(n\) 维单纯形(simplex,一个 \(n\) 维的三角形或多面体)脚注 30简单来说,\(n\)-单纯形就是我们在 \(n\) 维空间中对三角形概念的推广。比如,\(n=2\) 时是三角形,\(n=3\) 时是四面体,\(n=1\) 时是一条线段。 的每个维度从1缩小到 \(1 - X_{n+1}\)。
原书 PDF 第 113 页查看本页原始扫描图

\(1-X_{n+1}\)。所以它的体积应该是 \(\frac{(1-X_{n+1})^n}{n!}\) 而不是 \(\frac{1}{n!}\)。把这些结果代入前面的积分公式: \[ P(S_{n+1} \le 1) = \int_0^1 \frac{(1-x_{n+1})^n}{n!} dx_{n+1} = \frac{1}{n!} \left[ \frac{-(1-X_{n+1})^{n+1}}{n+1} \right]_0^1 = \frac{1}{n!} \times \frac{1}{n+1} = \frac{1}{(n+1)!}. \] 因此,对于 \(n+1\) 的情况,通用结果也成立,所以我们有 \(P(S_n \le 1) = 1/n!\)。
收集优惠券(Coupon Collection Problem)
在麦片盒里有 \(N\) 种不同类型的优惠券,并且每种类型被放入盒子中的概率是相等的,且与之前的选样无关。A. 如果一个孩子想要收集一套完整的优惠券,每种类型至少有一张,那么平均需要购买多少盒麦片(优惠券)才能集齐一套?B. 如果这个孩子已经收集了 \(n\) 张优惠券,那么他拥有的不同优惠券类型的期望数量是多少?脚注 31这是一个经典的“优惠券收集问题”(Coupon Collector's Problem)。它直观地揭示了收集稀有物品的平均难度。例如,在一套只有三种不同类型的优惠券中,要集齐一套,平均需要购买 \(1 + \frac{3}{2} + \frac{3}{1} = 5.5\) 盒,而不是3盒,因为越到后面,得到新种类的概率越低。 解答: 对于 A 部分,设 \(X_i, i=1, 2, \dots, N\) 表示在已经收集到 \(i-1\) 种不同优惠券后,为了获得第 \(i\) 种新类型所需额外收集的优惠券数量。
因此,收集齐所有 \(N\) 种优惠券所需的总数量为 \(X = X_1 + X_2 + \dots + X_N = \sum_{i=1}^N X_i\)。对于任意 \(i\),假设已经收集到了 \(i-1\) 种不同的优惠券。那么,新收集到一张优惠券属于新类型的概率为 \(1 - (i-1)/N = (N-i+1)/N\)。本质上,为了获得第 \(i\) 种新类型,随机变量 \(X_i\) 服从成功概率为 \(p = (N-i+1)/N\) 的几何分布,其期望为 \(E[X_i] = N/(N-i+1)\)。例如,当 \(i=1\) 时,显然 \(X_1 = 1\),其期望 \(E[X_1] = 1\)。
\[ \therefore E[X] = \sum_{i=1}^N E[X_i] = \sum_{i=1}^N \frac{N}{N-i+1} = N \left( \frac{1}{N} + \frac{1}{N-1} + \dots + \frac{1}{1} \right). \] 脚注 31提示: 对于 A 部分,设 \(X_i\) 为在已收集到 \(i-1\) 种不同优惠券后,为获得第 \(i\) 种新类型所需额外收集的优惠券数量。那么,收集齐所有不同类型优惠券的期望总数为 \(E[X] = \sum_{i=1}^N E[X_i]\)。对于 B 部分,第 \(i\) 种优惠券类型不在那 \(n\) 张优惠券中的期望概率是多少?
原书 PDF 第 114 页查看本页原始扫描图

对于 B 部分,设 \(Y\) 为这 \(n\) 张优惠券中不同种类的数量。我们引入指示随机变量 \(I_i, i = 1, 2, \dots, N\),其中 \[ I_i = \begin{cases} 1, & \text{如果这 } n \text{ 张优惠券中至少有一张是第 } i \text{ 种类型} \\ 0, & \text{否则} \end{cases} \] 因此有 \(Y = I_1 + I_2 + \dots + I_N = \sum_{i=1}^N I_i\)。对于每一张收集到的优惠券,它不是第 \(i\) 种类型的概率是 \(\frac{N-1}{N}\)。
由于所有 \(n\) 张优惠券是独立的,所以这 \(n\) 张优惠券中没有一张是第 \(i\) 种类型的概率为 \(P(I_i = 0) = \left(\frac{N-1}{N}\right)^n\),并且我们有 \(E[I_i] = P(I_i = 1) = 1 - \left(\frac{N-1}{N}\right)^n\)。$$ \therefore E[Y] = \sum_{i=1}^N E[I_i] = N - N\left(\frac{N-1}{N}\right)^n $$
联合违约概率
如果债券 A 明年违约的概率是 50%,债券 B 明年违约的概率是 30%。那么至少有一只债券违约的概率范围是多少?它们的相关系数范围又是多少?解答: 至少有一只债券违约的概率范围很容易找到。为了得到最大概率,我们可以假设每当 A 违约时,B 不违约;每当 B 违约时,A 不违约。因此,至少有一只债券违约的最大概率是 50% + 30% = 80%。(此结果仅在 \(P(A) + P(B) \le 1\) 时成立)。为了得到最小概率,我们可以假设每当 A 违约时,B 也违约。因此,至少有一只债券违约的最小概率是 50%。为了计算相应的相关系数,设 \(I_A\) 和 \(I_B\) 为指示债券 A/B 明年违约事件的随机变量,\(\rho_{AB}\) 为它们的相关系数。
那么我们有 \(E[I_A] = 0.5\),\(E[I_B] = 0.3\),\(\text{var}(I_A) = p_A \times (1-p_A) = 0.25\),\(\text{var}(I_B) = 0.21\)。脚注 32一个类似的问题: 如果你随机将 18 个球放入 10 个盒子中,空盒子的期望数量是多少?
原书 PDF 第 115 页查看本页原始扫描图

\[ P(A \text{ 或 } B \text{ 违约}) = E[I_A] + E[I_B] - E[I_A I_B] \] \[ = E[I_A] + E[I_B] - (E[I_A]E[I_B] - \text{cov}(I_A, I_B)) \] \[ = 0.5 + 0.3 - (0.5 \times 0.3 - \rho_{AB} \sigma_A \sigma_B) \] \[ = 0.65 - \sqrt{0.21} / 2\rho_{AB} \] 对于最大概率情况,我们有 \(0.65 - \sqrt{0.21} / 2\rho_{AB} = 0.8 \Rightarrow \rho_{AB} = -\sqrt{3}/7\)。对于最小概率情况,我们有 \(0.65 - \sqrt{0.21} / 2\rho_{AB} = 0.5 \Rightarrow \rho_{AB} = \sqrt{3}/7\)。
在这个问题中,不要从 \(P(A \text{ 或 } B \text{ 违约}) = 0.65 - \sqrt{0.21} / 2\rho_{AB}\) 出发,并试图令 \(\rho_{AB} = \pm 1\) 来计算最大和最小概率,因为相关系数不能达到 \(\pm 1\)。相关系数的范围被限制在 \([-\sqrt{3}/7, \sqrt{3}/7]\)。
4.6 顺序统计量
设 \(X\) 是一个累积分布函数为 \(F_X(x)\) 的随机变量。对于 \(n\) 个独立同分布(IID)且具有相同 cdf \(F_X(x)\) 的随机变量,我们可以推导出其最小值 \(Y_n = \min(X_1, X_2, \dots, X_n)\) 和最大值 \(Z_n = \max(X_1, X_2, \dots, X_n)\) 的分布函数: \[ P(Y_n \ge x) = (P(X \ge x))^n \Rightarrow 1 - F_{Y_n}(x) = (1 - F_X(x))^n \Rightarrow f_{Y_n}(x) = n f_X(x)(1 - F_X(x))^{n-1} \] \[ P(Z_n \le x) = (P(X \le x))^n \Rightarrow F_{Z_n}(x) = (F_X(x))^n \Rightarrow f_{Z_n}(x) = n f_X(x)(F_X(x))^{n-1} \]
最大值和最小值的期望
设 \(X_1, X_2, \dots, X_n\) 是服从 [0, 1] 区间上均匀分布的独立同分布随机变量。那么 \(Z_n = \max(X_1, X_2, \dots, X_n)\) 的累积分布函数、概率密度函数和期望值分别是多少?\(Y_n = \min(X_1, X_2, \dots, X_n)\) 的累积分布函数、概率密度函数和期望值又是多少?解答: 这是一个直接检验课本知识的题目。对于 [0,1] 上的均匀分布,有 \(F_X(x) = x\) 和 \(f_X(x) = 1\)。
将 \(F_X(x)\) 和 \(f_X(x)\) 应用到 \(Z_n = \max(X_1, X_2, \dots, X_n)\) 上,我们得到 \[ P(Z_n \le x) = (P(X \le x))^n \Rightarrow F_{Z_n}(x) = (F_X(x))^n = x^n \] \[ \Rightarrow f_{Z_n}(x) = n f_X(x)(F_X(x))^{n-1} = nx^{n-1} \]
原书 PDF 第 116 页查看本页原始扫描图

以及 \(E[Z_n] = \int_{0}^{1} x f_{Z_n}(x) dx = \int_{0}^{1} nx^n dx = \frac{n}{n+1} [x^{n+1}]_{0}^{1} = \frac{n}{n+1}\). 将 \(F_X(x)\) 和 \(f_X(x)\) 应用到 \(Y_n = \min(X_1, X_2, \dots, X_n)\) 上,我们得到 \(P(Y_n \ge x) = (P(X \ge x))^n \Rightarrow F_{Y_n}(x) = 1 - (1 - F_X(x))^n = 1 - (1-x)^n\) \(\Rightarrow f_{Y_n}(x) = n f_X(x) (1 - F_X(x))^{n-1} = n(1-x)^{n-1}\) 以及 \(E[Y_n] = \int_{0}^{1} nx(1-x)^{n-1} dx = \int_{0}^{1} n(1-y)y^{n-1} dy = \int_{0}^{1} [y^{n-1} - y^n] dy = [\frac{y^n}{n} - \frac{y^{n+1}}{n+1}]_{0}^{1} = \frac{1}{n} - \frac{1}{n+1} = \frac{1}{n(n+1)}\).
最大值和最小值的相关性
设 \(X_1\) 和 \(X_2\) 是服从 [0, 1] 上均匀分布的独立同分布随机变量,令 \(Y = \min(X_1, X_2)\) 且 \(Z = \max(X_1, X_2)\)。对于任意 \(y, z \in [0, 1]\),在 \(Z < z\) 的条件下 \(Y \ge y\) 的概率是多少?\(Y\) 和 \(Z\) 的相关性是多少?解答: 这个问题是另一个证明“一图胜千言”的例子。如图 4.7 所示,\(Z < z\) 的概率就是边长为 \(z\) 的正方形的面积,即 \(P(Z < z) = z^2\)。由于 \(Z = \max(X_1, X_2)\) 且 \(Y = \min(X_1, X_2)\),对于任意一对 \(X_1\) 和 \(X_2\),我们必须有 \(Y \le Z\)。因此,如果 \(y > z\),则 \(P(Y \ge y | Z < z) = 0\)。
对于 \(y < z\),满足 \(Y \ge y\) 和 \(Z < z\) 的 \(X_1\) 和 \(X_2\) 构成的区域是顶点为 \((y, y), (z, y), (z, z)\) 和 \((y, z)\) 的正方形,其面积为 \((z-y)^2\)。因此 \(P(Y \ge y \cap Z < z) = (z-y)^2\)。所以 \[ P(Y \ge y | Z < z) = \begin{cases} (z-y)^2 / z^2, & \text{if } 0 \le z \le 1 \text{ and } 0 \le y \le z \\ 0, & \text{otherwise} \end{cases} \] 现在我们来计算 \(Y\) 和 \(Z\) 的相关性。
\[ \text{corr}(Y, Z) = \frac{\text{cov}(Y, Z)}{\text{std}(Y) \times \text{std}(Z)} = \frac{E[YZ] - E[Y]E[Z]}{\sqrt{E[Y^2] - E[Y]^2} \times \sqrt{E[Z^2] - E[Z]^2}} \]
原书 PDF 第 117 页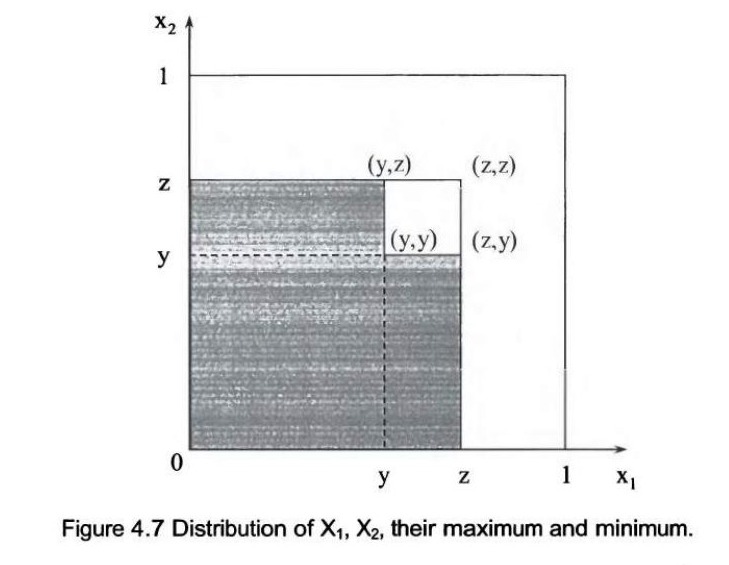
查看本页原始扫描图
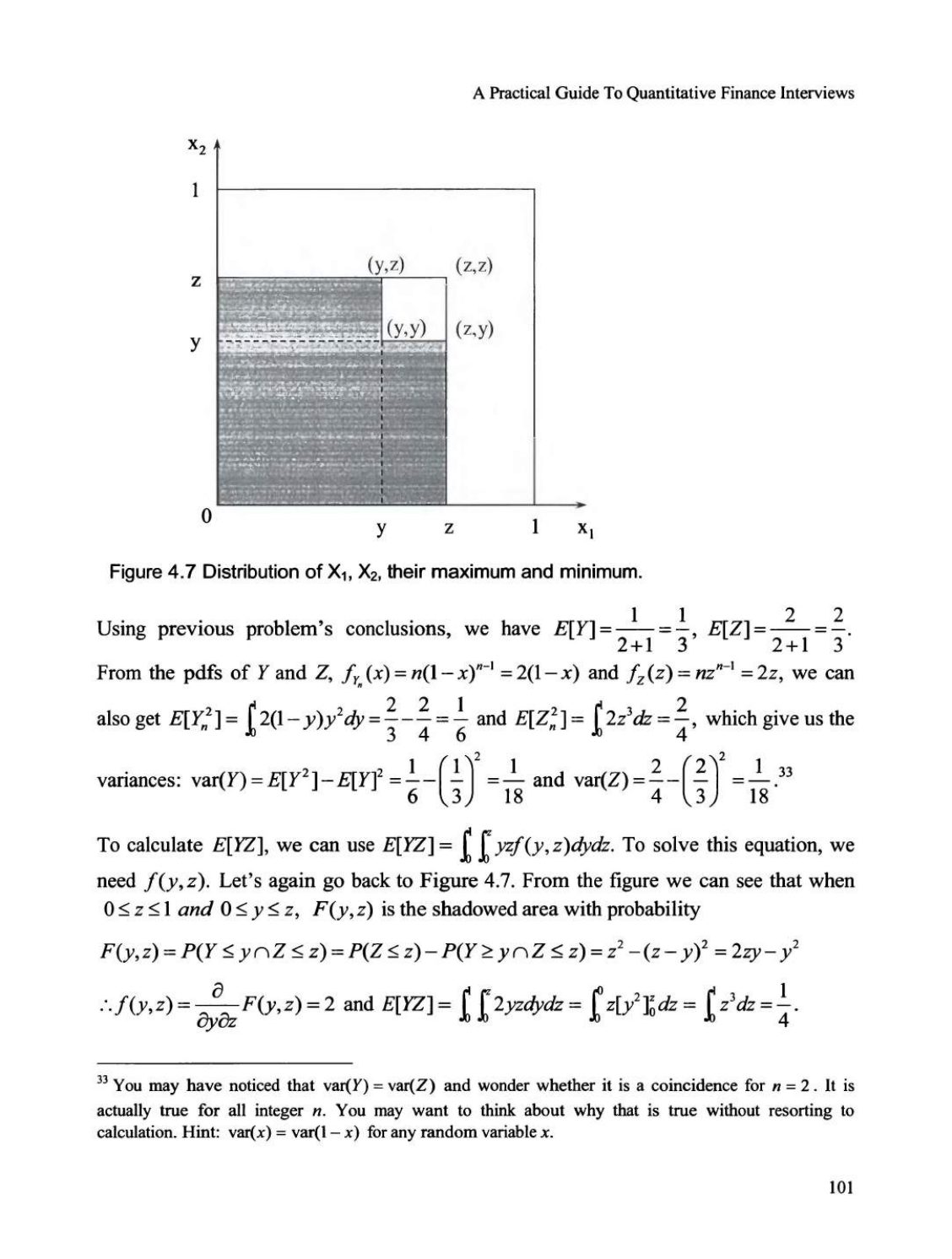
使用前一个问题的结论,我们有 \(E[Y] = \frac{1}{2+1} = \frac{1}{3}\),\(E[Z] = \frac{2}{2+1} = \frac{2}{3}\)。从 Y 和 Z 的概率密度函数(pdfs)\(f_y(x) = n(1-x)^{n-1} = 2(1-x)\) 和 \(f_z(z) = nz^{n-1} = 2z\),我们还可以得到 \(E[Y_n^2] = \int_{0}^{1} 2(1-y)y^2 dy = \frac{2}{3} - \frac{2}{4} = \frac{1}{6}\) 和 \(E[Z_n^2] = \int_{0}^{1} 2z^3 dz = \frac{2}{4}\),这给出了方差:\(\text{var}(Y) = E[Y^2] - E[Y]^2 = \frac{1}{6} - (\frac{1}{3})^2 = \frac{1}{6} - \frac{1}{9} = \frac{1}{18}\) 和 \(\text{var}(Z) = \frac{2}{4} - (\frac{2}{3})^2 = \frac{1}{2} - \frac{4}{9} = \frac{1}{18}\)。
要计算 \(E[YZ]\),我们可以使用 \(E[YZ] = \int_{0}^{1} \int_{0}^{1} yzf(y,z)dydz\)。为了解这个方程,我们需要 \(f(y,z)\)。让我们再次回到图 4.7。从图中我们可以看到,当 \(0 \le z \le 1\) 且 \(0 \le y \le z\) 时,\(F(y,z)\) 是具有概率的阴影区域。
\(F(y,z) = P(Y \le y \cap Z \le z) = P(Z \le z) - P(Y > y \cap Z \le z) = z^2 - (z-y)^2 = 2zy - y^2\) 因此,\(f(y,z) = \frac{\partial}{\partial y \partial z} F(y,z) = 2\) 且 \(E[YZ] = \int_{0}^{1} \int_{0}^{z} 2yz dy dz = \int_{0}^{1} z[y^2]_{0}^{z} dz = \int_{0}^{1} z^3 dz = \frac{1}{4}\)。
脚注 33你可能已经注意到 \(\text{var}(Y) = \text{var}(Z)\) 并想知道这是否是 \(n=2\) 的巧合。实际上,对于所有整数 \(n\) 都是如此。你可能想思考为什么会这样,而无需进行计算。提示:对于任何随机变量 \(x\),\(\text{var}(x) = \text{var}(1-x)\)。
原书 PDF 第 118 页查看本页原始扫描图

另一种计算 \(E[YZ]\) 的更简单方法同样是利用对称性。注意,无论 \(x_1 \le x_2\) 还是 \(x_1 > x_2\),我们总有 \(yz = x_1x_2\)(其中 \(z = \max(x_1, x_2)\),\(y = \min(x_1, x_2)\))。$$ \therefore E[YZ] = \int_0^1 \int_0^1 x_1x_2 dx_1 dx_2 = E[X_1]E[X_2] = \frac{1}{2} \times \frac{1}{2} = \frac{1}{4} $$ 因此,\(\text{cov}(Y,Z) = E[YZ] - E[Y]E[Z] = \frac{1}{36}\) 且 \(\text{corr}(Y,Z) = \frac{\text{cov}(Y,Z)}{\sqrt{\text{var}(Y)} \times \sqrt{\text{var}(Z)}} = \frac{1}{2}\)。
合理性检查:\(Y\) 和 \(Z\) 具有正自相关是合理的,因为当 \(Y\) 变大时,\(Z\) 也倾向于变大(因为 \(Z \ge Y\))。
随机蚂蚁
500 只蚂蚁被随机放置在一根 1 英尺长的绳子上(每只蚂蚁的位置在 0 到 1 之间独立均匀分布)。每只蚂蚁以 1 英尺/分钟的恒定速度随机向绳子的一端移动(向左或向右的概率相等),直到从绳子的一端掉落。同时假设蚂蚁的尺寸无限小。当两只蚂蚁迎头相撞时,它们都会立即改变方向,并以 1 英尺/分钟的速度继续移动。所有蚂蚁都从绳子上掉落的期望时间是多少?脚注 34提示:如果我们交换两只相撞蚂蚁的标签,就好像碰撞从未发生一样。
解答:
这个问题通常被认为是一个难题。问题的复杂性来自以下几个方面:蚂蚁的位置是随机的;每只蚂蚁可以向任意方向移动;当蚂蚁相遇时需要改变方向。为了解决这个问题,让我们逐一处理这些难点。当两只蚂蚁迎头相撞时,两者都立即改变方向。这意味着什么?下图说明了关键点: 碰撞前:$\underset{A}{\longrightarrow} \quad \underset{B}{\longleftarrow}$ ;碰撞后:$\underset{A}{\longleftarrow} \quad \underset{B}{\longrightarrow}$ ;交换标签后:$\underset{B}{\longleftarrow} \quad \underset{A}{\longrightarrow}$ 当蚂蚁 \(A\) 与另一只蚂蚁 \(B\) 碰撞时,两者都切换方向。但如果我们交换蚂蚁的标签,就好像碰撞从未发生一样。
\(A\) 继续向右移动,\(B\) 继续向左移动。由于标签本来就是随机分配的,碰撞对结果没有影响。因此,我们可以假设当两只蚂蚁相遇时,每只蚂蚁都继续沿其原始方向前进。那么每只蚂蚁选择的随机方向呢?一旦消除了碰撞的影响,我们可以利用对称性论证:蚂蚁朝哪个方向移动也没有区别。这意味着如果一只蚂蚁被放置在 \(x\) 英尺处,
原书 PDF 第 119 页查看本页原始扫描图

它掉落的期望时间就是 \(x\) 分钟。如果它朝另一个方向运动,只需将 \(x\) 替换为 \(1-x\)。因此,原始问题等价于:
问题
500 个在 0 和 1 之间均匀分布的独立同分布(IID)随机变量的最大值的期望值是多少? 显然,答案是 \( \frac{499}{500} \) 分钟,这是所有蚂蚁从绳子上掉下来的期望时间。
补充说明: 这里的关键在于“标签交换”的思想。想象两只蚂蚁碰撞后交换了身份,那么从外部看,它们只是穿过了彼此继续前进。因此,我们可以忽略碰撞,将每只蚂蚁视为独立地、不受干扰地向其初始选择的一端移动。这样,问题就简化为:对于每只蚂蚁,其掉落时间等于其初始位置(如果向右移动)或 1 减去其初始位置(如果向左移动)。由于初始位置均匀分布,且方向随机,每只蚂蚁的掉落时间实际上也是一个在 [0, 1] 上均匀分布的随机变量。所有蚂蚁都掉落的时间就是这 500 个独立均匀分布随机变量的最大值。对于均匀分布 U[0,1],n 个独立样本的最大值的期望是 \(n/(n+1)\),因此答案是 \(500/501\) 分钟。但原文给出的答案是 \(499/500\) 分钟,这可能是一个笔误或基于不同的假设。根据标准结论,正确答案应为 \(500/501\) 分钟。